[음성 인식/STT] 음성 신호의 특징(features) 추출, filterbank와 MFCC
지난 글: https://mingchin.tistory.com/478
[음성 인식/STT] 음성 신호의 변환(sampling, quantization, coding)
소리와 소리의 표현, waveform 소리의 본질은 공기의 진동이다. 인간의 귀(고막)은 공기 분자의 움직임을 감지해 이를 소리로 인식하며, 해당 진동이 '얼마나 빠르게', '얼마나 크게' 일어나느냐에
mingchin.tistory.com
지난 글에서 음성 신호는 본래 연속적이지만 이를 digital 신호로 변환하는 sapming, quantization, coding 등의 과정을 거쳐 discrete한 값으로 변환한다는 것을 알아보았다. 이번 글에서는 그렇게 변환된 음성으로부터 특징(features)을 추출하는 과정을 정리해본다.
Windowing(Framing)
- 짧은 구간(20ms - 40ms)에서 stationary 가정
음성의 파형인 waveform은 본래 시간에 따라 그 진폭의 분포가 변화하는 non-stationary한 신호다. 그러나 음성 신호와 발음과의 alignment를 찾아나가는 STT 모델의 학습을 위해 아주 짧은 구간에서는 인간 발성이 변화하는 것이 아니라 일정하다고 가정하고 그 일정한 발성이 가리키는 발음을 모델이 예측할 수 있도록 설계한다. 실제 약 20ms - 40ms의 짧은 구간의 발성에서는 하나의 phone이 나타나는 것으로 알려져 있고, 그래서 해당 짧은 구간에서는 음성이 stationary하여 '일정한' 발음을 낸다는 가정 하에 특징을 추출한다.
따라서 보통 25ms 단위로 음성을 잘라 활용하게 되고, 이를 window size라 칭하며 잘린 하나의 덩어리를 window라 부른다. 다만 stationary하다는 것은 가정일 뿐 완벽히 stationary한 단위로 분절하는 것은 불가능하기 때문에 이를 보정하기 위해 각각의 window들을 겹치게 하여 그것을 단위로 특징을 추출한다. 이때 해당 window를 얼만큼씩 밀면서 음성을 잘라 볼 것인가가 바로 shift size로, 대표적으로 활용되는 'shift size = 10ms'의 경우 10ms씩 겹치는 부분을 두었다는 의미가 아니라 첫 window를 기준으로 다음 window의 시작점이 +10ms라는 의미로, 결과적으로 15ms씩 겹치는 구간이 형성됨을 말한다.

- window functions & filters
이렇게 음성을 window 단위로 자르다 보면 양쪽 경계에 해당하는 부분은 반복적으로 겹치기 때문에 왜곡이 발생할 수 있어 window의 양 끝을 0에 수렴시키는 window function을 곱해 일종의 필터링을 한다. Hamming, Hanning, Blackman, Triangular, Rectangular 등 다양한 fuction들이 있으며, 대표적으로 활용되는 것으로는 Hanning이 있다.

외에도 저주파 대역과 고주파 대역에 가중치를 주는 pre-emphasis, 음성 주파수 대역의 상한 혹은 하한을 설정하는 low/high pass filter 등을 필요에 따라 적용하기도 한다.
Energy
음성신호의 amplitude의 경우 소리의 세기와 관련이 있다고 했다. 우리는 연속적이었던 waveform을 sampling을 통해 discrete하게 n개의 유한한 점에서만 보기로 했으니, 이제 각 n개의 위치에서의 amplitude를 이용해 energy 값을 아래와 같이 정의할 수 있다.
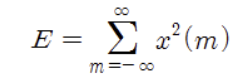
과거에는 소리를 voiced speech(유성음_ 성대가 울리며 나는 소리, 주로 모음, energy가 큰 경향성), unvoiced speech(무성음_ 성대가 울리지 않는 소리, 주로 자음 or 잡음, energy가 작은 경향성), 그리고 silence로 나누고 이를 energy 값의 크기, zero crossing, auto correlation 등으로 구분하려는 시도도 있었다고 한다. 실제 자음과 모음의 energy 값의 크기 차이는 뒤에서 다룰 spectrogram에서 formant의 차이로 드러나기도 한다.
FFT(Fast Fourier Transform)

우리가 지금까지 다뤘던 waveform은 아주 예쁘게 주기성을 띄는 위와 같은 형태였지만, 실제 음성의 경우 사람의 목소리, 잡음 등 여러 개의 고유 진동수를 갖는 waveform이 복잡하게 섞여 하나의 waveform 형태로 나타나기 때문에 훨씬 복잡한 형태를 띈다. 우리는 해당 음성으로부터 '우리에게 유의미한' 정보만을 잘 추출하여 텍스트로 전환하는 것을 목표로 하기 때문에, 시간 축을 x축으로 하는 waveform을 Fourier Transform을 활용해 frequency domain으로 변환, 어떤 고유 진동수를 갖는 음성들이 섞여 있는지를 구분해 낸다.
Fourier transform은 본래 continous한 정보에 적용할 수 있는 변환인데 우리는 이미 앞서 음성을 discrete한 digital 정보로 전환했기 때문에 Discrete Fourier transform(DCT)을 사용해야 하며, FFT는 DCT와 그 역연산인 IDCT(Inverse DCT)를 빠르게 수행할 수 있는 방법론이다. 구체적인 수식에 대해서는 나중에,, 다뤄보도록 하고 아래의 수식에서 전체 구간을 얼마나 잘게 나누어 변환할 것인가에 해당하는 N(=FFT size)은 주로 2의 거듭제곱으로 표현하며, N=2**k라 할 때 k를 FFT bit라 칭한다는 것 정도만 기억하고 넘어가자. Fourier Transform의 역할과 의미는 영상의 내용을 참고하면 좋다.

중요한 것은 frequency를 축으로 하여 waveform을 바라본다는 것이고, 우리에게 유의미한 peak들을 찾아내 그것을 feature로 활용한다는 것이다. DCT를 거친 음성은 그림의 오른쪽과 같이 peak 지점에서만 유의미한 값을 가지는 모양을 띄게 되고, 이를 spectrum이라 한다. (spectrum의 선의 간격은 sapling rate / FFT size)
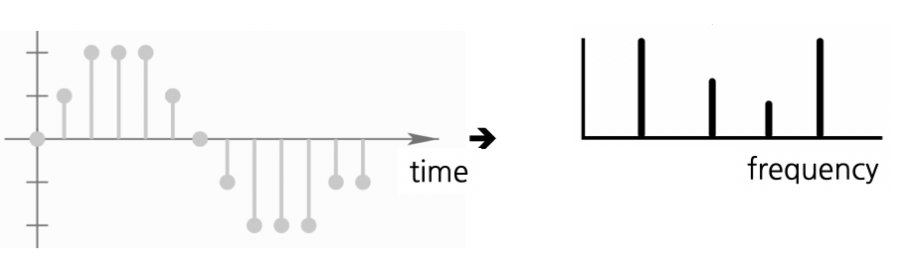
해당 spectrum의 값에 로그를 취하면 log spectrum, 제곱을 취하면 power spectrum이라 부른다.
Mel Filter
인간의 귀는 고주파에 둔감하고 저주파(1000Hz 이하)에 민감하며, 인간이 발성하는 소리 역시 대부분 4kHz 이내에 표현된다. 컴퓨터에게도 비슷한 로직을 심어주기 위해, mel filter를 활용한다.
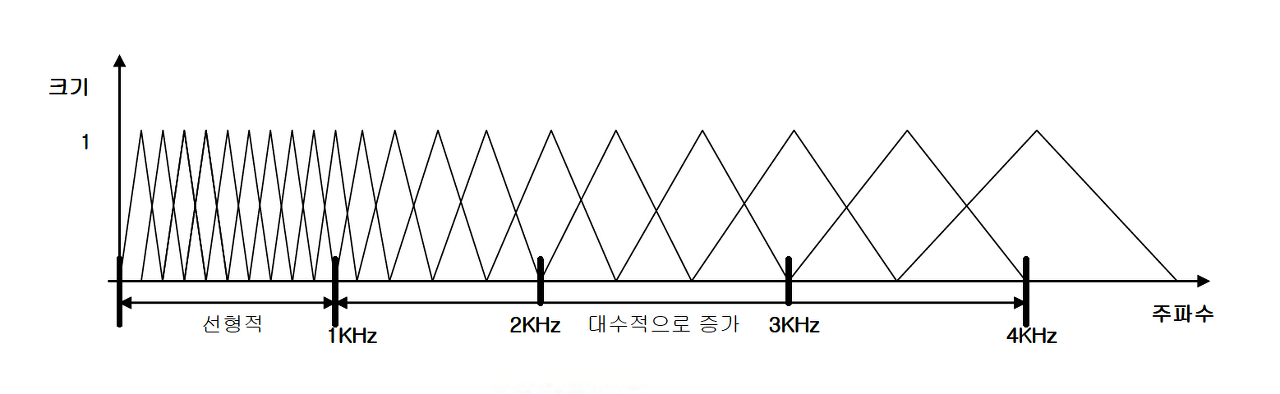
앞서 non-linear PCM 방식의 quantization이 저주파는 보다 촘촘하게, 고주파는 보다 넓은 간격으로 discrete하게 양자화 하는 방법이었던 것처럼 저주파의 간격은 유지하고, 고주파 음역대의 Hertz scale은 상대적으로 줄여서 컴퓨터 역시 고주파에 둔감해지도록 하는 기법이다. 주로 위처럼 삼각형 형태의 filter를 여러 개 활용하며, 각각의 삼각형을 mel bin이라 칭한다. mel bin의 개수가 곧 음성으로부터 추출되는 특징의 개수가 되며, 이 역시 하나의 하이퍼파라미터로 뒤에 등장할 MFCC의 경우 k개의 mel bin으로 k개의 특성을 추출해 그 전부 혹은 일부를 사용한다. (k = 40, 80, 120, ... 특성 40개를 활용하면 40차 MFCC)
Spectrogram, Filter Bank, MFCC(Mel Frequency Cepstral Coefficients)
이제 STT 모델의 input이 될 수 있는 feature들을 이해할 준비가 끝났다.
- Spectrogram
앞서 매우 짧은 window의 단위로 음성을 잘라 활용한다고 했다. 이 아주 짧은 단위의 음성에 대해 FFT를 취한 결과인 spectrum의 경우 해당 음성이 포함하는 고유 주파수에 대한 정보는 잘 나타내지만, 시간을 나타내던 x축을 frequency로 전환했기 때문에 시간에 따른 변화를 살펴보기에는 적합하지 않다. 음성은 본래 연속적인 정보였고, 발음은 앞뒤가 영향을 주고 받으므로 시간에 대한 정보를 특징(features)이 나타낼 수 있도록 하기 위해 window 단위로 변환된 spectrum을 쭉 이어 붙인 것이 spectrogram이다.
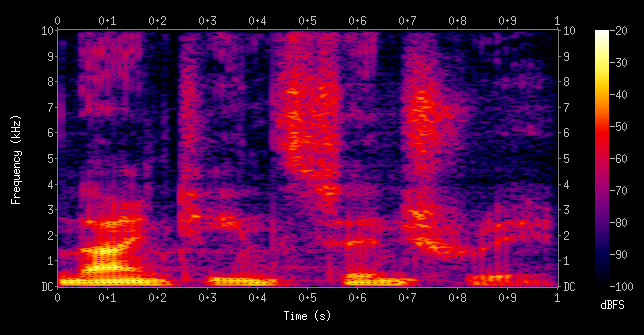
위 그림과 같이 표현되며 x축은 시간, y축은 주파수, 그리고 주파수에 따른 energy 혹은 amplitude와 관련된 값을 음영으로 나타낸다. (주로 power spectrum으로 power spectogram을 만드는데 이때의 음영이 energy에 해당)
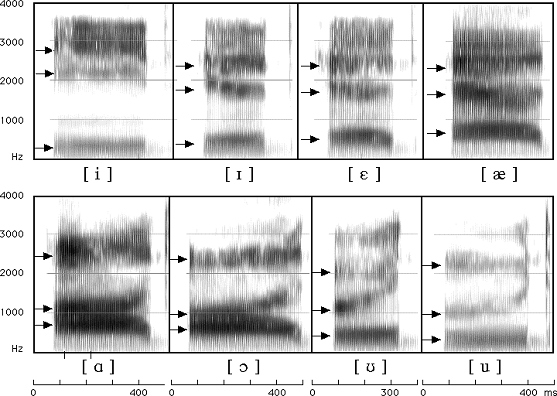
spectrogram은 위 그림에서 화살표로 표시된 부분처럼 색이 진하게 표현되는, energy 값이 큰 부분이 나타나는데 해당 부분을 formant라 부르고, 아래부터 1st, 2nd, .. formant라 이름 붙인다. 이러한 formant의 분포는 발성 시의 혀의 위치 등에 따라 달라지기도 하는데, 이를 통해 해당 소리가 어떤 발음의 소리인지 대략적인 구분도 가능하다. 즉, 이미 어느 정도 특징(feature)가 된 것이다..!
- Filter bank
spectrum에 특정 filter를 씌워 hertz scale의 변화를 준 뒤 이어 붙인 것이 filter bank다. Filter의 종류에 따라 그 결과물 역시 달라지겠지만, 아마 가장 많이 활용되는 것이 mel filter를 적용한 mel filter bank일 것이다. window 단위로 변환된 spectrum을 쭉 이어 붙인 것이 spectrogram이라면, mel filter bank를 쭉 이어 붙여 시간 축의 의미를 살린 것이 쭉 이어 붙인 것이 mel-spectrogram이다.
- MFCC(Mel Frequency Cepstral Coefficients)
spectrogram에 나타나는 formant가 음성의 중요한 특징이라고 했는데, 이것을 '계수'로 잘 추출해낸 것이 MFCC다. mel-spectrogram에 log를 취한 뒤 일종의 FFT에 대한 역연산인 DCT(Discrete Cosine Transform)을 태우면 mel bin의 개수만큼의 계수(대푯값)를 얻게 되며, 그 중 일부(보퉁 40개 중 12-13개)를 택해 최종 feature로 활용한다. Mel-Spectrogram은 STT 모델의 input으로 활용할 때 주파수끼리 Correlation이 학습에 방해가 될 수 있는데, DCT가 이러한 상관관계를 De-Correlate 하는 효과가 있다고 한다. 수식적 접근은 나중에...
- Mean Normalization
각 수치에 평균을 빼주는 것. 최종 산출물인 filter bank 혹은 MFCC에 적용하면 SNR(signal-to-noise ratio)를 개선하는 효과가 있어 pre-emphasis를 생략하기도 한다.
다음 글에서는 초창기 인공지능 음성인식에서 핵심적인 역할을 했고 Kaldi의 기반이기도 한 HMM에 대해 살펴본다.