[Rust] CER과 WER 계산하기
세부 목표 설정
Rust 언어를 보다 재밌고 효율적으로 공부하기 위해 아래의 기능을 가진 안드로이드 앱을 만들어 볼 예정이다.
- 두 개의 빈 텍스트를 입력할 수 있는 공간을 가짐
- 셋 중 하나의 eval metric을 설정 가능(CER / WER / ALL)
- 두 개의 문장을 입력 후, "calculate"을 누르면 두 문장의 metric을 연산 후 TMSID를 포함해 출력
간단한 기능이지만 난 안드로이드의 a도 모르기 때문에.. 험난한 여정이 될 것이다.
CER / WER 연산하기
Copilot에게 CER에 대해서 설명하고, 띄어쓰기의 경우 음절에서 배제해야 한다는 사실을 말해주었더니 그럭저럭 기능하는 코드를 주었다.
use std::io::{self, Write};
struct CerResult {
total: usize,
match_count: usize,
substitution_count: usize,
insertion_count: usize,
deletion_count: usize,
cer: f64,
}
fn calculate_errors(hyp: &str, ref_: &str) -> (usize, usize, usize, usize) {
let hyp_chars: Vec<char> = hyp.chars().filter(|c| !c.is_whitespace()).collect();
let ref_chars: Vec<char> = ref_.chars().filter(|c| !c.is_whitespace()).collect();
let mut match_count = 0;
let mut substitution_count = 0;
let mut insertion_count = 0;
let mut deletion_count = 0;
let mut i = 0;
let mut j = 0;
while i < hyp_chars.len() && j < ref_chars.len() {
if hyp_chars[i] == ref_chars[j] {
match_count += 1;
i += 1;
j += 1;
} else {
substitution_count += 1;
i += 1;
j += 1;
}
}
if i < hyp_chars.len() {
insertion_count = hyp_chars.len() - i;
}
if j < ref_chars.len() {
deletion_count = ref_chars.len() - j;
}
(match_count, substitution_count, insertion_count, deletion_count)
}
fn calculate_cer(hyp: &str, ref_: &str) -> CerResult {
let (match_count, substitution_count, insertion_count, deletion_count) = calculate_errors(hyp, ref_);
let total_chars = ref_.chars().filter(|c| !c.is_whitespace()).count();
let cer = (substitution_count + insertion_count + deletion_count) as f64 / total_chars as f64;
CerResult {
total: total_chars,
match_count,
substitution_count,
insertion_count,
deletion_count,
cer,
}
}
fn main() {
let mut ref_input = String::new();
let mut hyp_input = String::new();
print!("Enter the reference sentence: ");
io::stdout().flush().unwrap();
io::stdin().read_line(&mut ref_input).unwrap();
let ref_input = ref_input.trim();
print!("Enter the hypothesis sentence: ");
io::stdout().flush().unwrap();
io::stdin().read_line(&mut hyp_input).unwrap();
let hyp_input = hyp_input.trim();
let result = calculate_cer(hyp_input, ref_input);
println!("Total: {}", result.total);
println!("Match: {}", result.match_count);
println!("Substitution: {}", result.substitution_count);
println!("Insertion: {}", result.insertion_count);
println!("Deletion: {}", result.deletion_count);
println!("CER: {:.4}", result.cer);
}
"ref"의 경우 예약어로 사용할 수 없어 ref_로 대체를 요청했다.
대충 살펴보니.. 앞 음절부터 순차적으로 탐색하기 때문에, 정확한 편집거리를 계산해 줄 수 없는 상태였다.
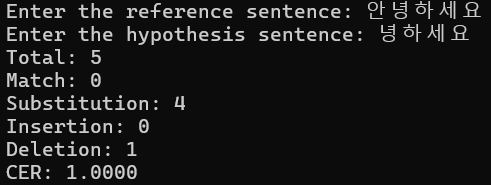
당연히 위와 같은 오류를 범하게 된다. 그래서 Levenshtein edit distance의 개념을 사용해 음절을 연산해달라고 요청했다. 이를 위해서는 외부 패키지인 edit_distance하고, 그래서 이를 Catgo.toml 내 dependency에 아래와 같이 추가해준다.
[dependencies]
edit-distance = "2.0"
이 문제는 chars() 메서드가 UTF-8 문자로 문자열을 처리하기 때문에 발생할 수 있습니다. chars() 메서드는 각 문자를 UTF-8 코드 포인트로 처리하므로, 한글 문자 하나가 여러 개의 코드 포인트로 인식될 수 있습니다. 이를 해결하기 위해
graphemes 메서드를 사용하여 유니코드 그래프 클러스터를 처리할 수 있습니다.
오.. UTF8에서 한글이 3음절로 다루어지기 때문에 Total이 3배가 돼서 나온 것 같다. 그래서 이를 해결한 최종 코드는
use std::io::{self, Write};
use edit_distance::edit_distance;
use unicode_segmentation::UnicodeSegmentation;
struct CerResult {
total: usize,
match_count: usize,
substitution_count: usize,
insertion_count: usize,
deletion_count: usize,
cer: f64,
}
fn calculate_cer(hyp: &str, ref_: &str) -> CerResult {
let hyp_chars: Vec<&str> = hyp.graphemes(true).filter(|c| !c.chars().all(char::is_whitespace)).collect();
let ref_chars: Vec<&str> = ref_.graphemes(true).filter(|c| !c.chars().all(char::is_whitespace)).collect();
let hyp_str: String = hyp_chars.concat();
let ref_str: String = ref_chars.concat();
let distance = edit_distance(&hyp_str, &ref_str);
let total_chars = ref_chars.len();
let cer = distance as f64 / total_chars as f64;
let mut match_count = 0;
let mut substitution_count = 0;
let mut insertion_count = 0;
let mut deletion_count = 0;
let mut i = 0;
let mut j = 0;
while i < hyp_chars.len() && j < ref_chars.len() {
if hyp_chars[i] == ref_chars[j] {
match_count += 1;
i += 1;
j += 1;
} else {
substitution_count += 1;
i += 1;
j += 1;
}
}
if i < hyp_chars.len() {
insertion_count = hyp_chars.len() - i;
}
if j < ref_chars.len() {
deletion_count = ref_chars.len() - j;
}
CerResult {
total: total_chars,
match_count,
substitution_count,
insertion_count,
deletion_count,
cer,
}
}
fn main() {
let mut ref_input = String::new();
let mut hyp_input = String::new();
print!("Enter the reference sentence: ");
io::stdout().flush().unwrap();
io::stdin().read_line(&mut ref_input).unwrap();
let ref_input = ref_input.trim();
print!("Enter the hypothesis sentence: ");
io::stdout().flush().unwrap();
io::stdin().read_line(&mut hyp_input).unwrap();
let hyp_input = hyp_input.trim();
let result = calculate_cer(hyp_input, ref_input);
println!("Total: {}", result.total);
println!("Match: {}", result.match_count);
println!("Substitution: {}", result.substitution_count);
println!("Insertion: {}", result.insertion_count);
println!("Deletion: {}", result.deletion_count);
println!("Total Errors: {}", result.substitution_count + result.insertion_count + result.deletion_count);
println!("CER: {:.4}", result.cer);
}
하지만 자세히 보니.. 다시 앞에서부터 순차 계산을 하는 코드를 뱉어내며 레퍼런스를 던져주고 뭔 짓을 해봐도 같은 코드를 뱉어내기 시작했다. 그래서 클로드를 써보기로..
일단 첫 구현체부터 훨씬 나은 모습을 보여줬다. 직접 Levenshtein edit distance 계산을 구현하고, 그 결과를 출력하고자 했다. 하지만 유사하게 encoding 관련 오차가 있었고, 이를 지적해도 제대로 해결되지 않았다. 그레서 아래의 파이썬 레퍼런스를 던져주고, 이걸 참고해서 수정해보라고 했다.
def word_error_rate_detail(
hypotheses: List[str], references: List[str], use_cer=False
) -> Tuple[float, int, float, float, float]:
"""
Computes Average Word Error Rate with details (insertion rate, deletion rate, substitution rate)
between two texts represented as corresponding lists of string.
Hypotheses and references must have same length.
Args:
hypotheses (list): list of hypotheses
references(list) : list of references
use_cer (bool): set True to enable cer
Returns:
wer (float): average word error rate
words (int): Total number of words/charactors of given reference texts
ins_rate (float): average insertion error rate
del_rate (float): average deletion error rate
sub_rate (float): average substitution error rate
"""
scores = 0
words = 0
ops_count = {'substitutions': 0, 'insertions': 0, 'deletions': 0}
if len(hypotheses) != len(references):
raise ValueError(
"In word error rate calculation, hypotheses and reference"
" lists must have the same number of elements. But I got:"
"{0} and {1} correspondingly".format(len(hypotheses), len(references))
)
for h, r in zip(hypotheses, references):
if use_cer:
h_list = list(h)
r_list = list(r)
else:
h_list = h.split()
r_list = r.split()
# To get rid of the issue that jiwer does not allow empty string
if len(r_list) == 0:
if len(h_list) != 0:
errors = len(h_list)
ops_count['insertions'] += errors
else:
errors = 0
else:
if use_cer:
measures = jiwer.cer(r, h, return_dict=True)
else:
measures = jiwer.compute_measures(r, h)
errors = measures['insertions'] + measures['deletions'] + measures['substitutions']
ops_count['insertions'] += measures['insertions']
ops_count['deletions'] += measures['deletions']
ops_count['substitutions'] += measures['substitutions']
scores += errors
words += len(r_list)
if words != 0:
wer = 1.0 * scores / words
ins_rate = 1.0 * ops_count['insertions'] / words
del_rate = 1.0 * ops_count['deletions'] / words
sub_rate = 1.0 * ops_count['substitutions'] / words
else:
wer, ins_rate, del_rate, sub_rate = float('inf'), float('inf'), float('inf'), float('inf')
return wer, words, ins_rate, del_rate, sub_rate
그랬더니, 마지막 출력부 정도만 원하는 대로 조금 손보면 되는 코드를 잘 던져주었다.
use std::io;
use unicode_segmentation::UnicodeSegmentation;
fn compute_error_rate(hyp: &str, ref_str: &str, use_cer: bool) -> (usize, usize, usize, usize) {
let (hyp_list, ref_list) = if use_cer {
(
hyp.graphemes(true).collect::<Vec<&str>>(),
ref_str.graphemes(true).collect::<Vec<&str>>()
)
} else {
(
hyp.split_whitespace().collect::<Vec<&str>>(),
ref_str.split_whitespace().collect::<Vec<&str>>()
)
};
if ref_list.is_empty() {
return if hyp_list.is_empty() {
(0, 0, 0, 0) // No errors
} else {
(hyp_list.len(), hyp_list.len(), 0, 0) // All insertions
};
}
let m = hyp_list.len();
let n = ref_list.len();
// 레벤슈타인 거리 행렬
let mut dp = vec![vec![0; n + 1]; m + 1];
for i in 0..=m { dp[i][0] = i; }
for j in 0..=n { dp[0][j] = j; }
// 작업 추적 행렬
let mut ops = vec![vec![0; n + 1]; m + 1];
for i in 1..=m {
for j in 1..=n {
if hyp_list[i-1] == ref_list[j-1] {
dp[i][j] = dp[i-1][j-1];
ops[i][j] = 0; // 매치
} else {
let sub = dp[i-1][j-1] + 1;
let del = dp[i-1][j] + 1;
let ins = dp[i][j-1] + 1;
dp[i][j] = sub.min(del).min(ins);
ops[i][j] = if dp[i][j] == sub { 1 } // 대체
else if dp[i][j] == del { 2 } // 삭제
else { 3 }; // 삽입
}
}
}
// 오류 계산
let mut substitutions = 0;
let mut deletions = 0;
let mut insertions = 0;
let errors = dp[m][n];
// 역추적으로 오류 타입 분류
let mut i = m;
let mut j = n;
while i > 0 && j > 0 {
match ops[i][j] {
1 => { substitutions += 1; i -= 1; j -= 1; }
2 => { deletions += 1; i -= 1; }
3 => { insertions += 1; j -= 1; }
_ => { i -= 1; j -= 1; }
}
}
// 남은 삽입/삭제 처리
insertions += j;
deletions += i;
(errors, insertions, deletions, substitutions)
}
fn calculate_error_rate(hypotheses: &[String], references: &[String], use_cer: bool) -> (f64, usize, usize, usize, usize) {
let mut total_errors = 0;
let mut total_words = 0;
let mut total_insertions = 0;
let mut total_deletions = 0;
let mut total_substitutions = 0;
for (h, r) in hypotheses.iter().zip(references.iter()) {
let (errors, insertions, deletions, substitutions) = compute_error_rate(h, r, use_cer);
total_errors += errors;
total_words += if use_cer {
r.graphemes(true).count()
} else {
r.split_whitespace().count()
};
total_insertions += insertions;
total_deletions += deletions;
total_substitutions += substitutions;
}
let error_rate = if total_words > 0 {
total_errors as f64 / total_words as f64
} else {
f64::INFINITY
};
(error_rate, total_words, total_insertions, total_deletions, total_substitutions)
}
fn main() {
println!("Enter the hypothesis sentence:");
let mut hyp = String::new();
io::stdin().read_line(&mut hyp).expect("Failed to read line");
let hyp = hyp.trim().to_string();
println!("Enter the reference sentence:");
let mut ref_str = String::new();
io::stdin().read_line(&mut ref_str).expect("Failed to read line");
let ref_str = ref_str.trim().to_string();
let (error_rate, total_words, total_insertions, total_deletions, total_substitutions) =
calculate_error_rate(&[hyp], &[ref_str], true);
println!("\nCER Calculation Results:");
println!("CER: {:.2}%", error_rate * 100.0);
println!("Total Chars: {}", total_words);
println!("Total Ins: {}", total_insertions);
println!("Total Del: {}", total_deletions);
println!("Total Sub: {}", total_substitutions);
}
놀라운 것은 " jiwer 라이브러리의 기능을 직접 구현해야 할 것 같네요. " 라고 말한 뒤 세부 error 계산을 위한 로직을 알아서 구현했다는 점.. 하지만 그럼에도 정확한 구현은 아니었다.
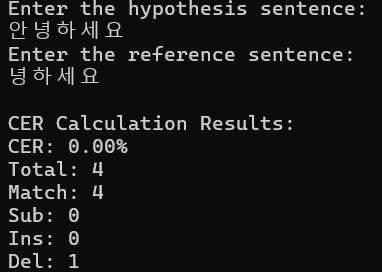
결국 세부 연산까지 포함한 레퍼런스까지 던져준 후에야 정확한 코드를 받을 수 있었다.
use std::collections::HashMap;
use unicode_segmentation::UnicodeSegmentation;
use std::io::{self};
#[derive(Debug)]
struct EditResult {
distance: Vec<Vec<usize>>,
steps: Vec<char>,
}
fn edit_distance(reference: &[&str], hypothesis: &[&str]) -> EditResult {
let m = reference.len();
let n = hypothesis.len();
let mut d = vec![vec![0; n + 1]; m + 1];
// Initialize first row and column
for i in 0..=m {
d[i][0] = i;
}
for j in 0..=n {
d[0][j] = j;
}
// Compute edit distance matrix
for i in 1..=m {
for j in 1..=n {
if reference[i - 1] == hypothesis[j - 1] {
d[i][j] = d[i - 1][j - 1];
} else {
let substitute = d[i - 1][j - 1] + 1;
let insert = d[i][j - 1] + 1;
let delete = d[i - 1][j] + 1;
d[i][j] = substitute.min(insert).min(delete);
}
}
}
// Backtrack to get steps
let mut steps = Vec::new();
let mut x = m;
let mut y = n;
while x > 0 || y > 0 {
if x > 0 && y > 0 && reference[x - 1] == hypothesis[y - 1] {
steps.push('e');
x -= 1;
y -= 1;
} else if y > 0 && d[x][y] == d[x][y - 1] + 1 {
steps.push('i');
y -= 1;
} else if x > 0 && y > 0 && d[x][y] == d[x - 1][y - 1] + 1 {
steps.push('s');
x -= 1;
y -= 1;
} else if x > 0 {
steps.push('d');
x -= 1;
}
}
steps.reverse();
EditResult {
distance: d,
steps,
}
}
fn calculate_cer(reference: &str, hypothesis: &str) -> HashMap<String, f64> {
let ref_chars: Vec<&str> = reference.graphemes(true).collect();
let hyp_chars: Vec<&str> = hypothesis.graphemes(true).collect();
let result = edit_distance(&ref_chars, &hyp_chars);
let steps = result.steps;
let distance = result.distance[ref_chars.len()][hyp_chars.len()];
let total = ref_chars.len();
let counter: HashMap<char, usize> = steps.iter()
.fold(HashMap::new(), |mut acc, &step| {
*acc.entry(step).or_insert(0) += 1;
acc
});
let error_rate = if total > 0 {
(distance as f64 / total as f64) * 100.0
} else {
0.0
};
HashMap::from([
("cer".to_string(), error_rate),
("tot".to_string(), total as f64),
("mat".to_string(), *counter.get(&'e').unwrap_or(&0) as f64),
("sub".to_string(), *counter.get(&'s').unwrap_or(&0) as f64),
("del".to_string(), *counter.get(&'d').unwrap_or(&0) as f64),
("ins".to_string(), *counter.get(&'i').unwrap_or(&0) as f64),
])
}
fn calculate_wer(reference: &str, hypothesis: &str) -> HashMap<String, f64> {
let ref_words: Vec<&str> = reference.split_whitespace().collect();
let hyp_words: Vec<&str> = hypothesis.split_whitespace().collect();
let result = edit_distance(&ref_words, &hyp_words);
let steps = result.steps;
let distance = result.distance[ref_words.len()][hyp_words.len()];
let total = ref_words.len();
let counter: HashMap<char, usize> = steps.iter()
.fold(HashMap::new(), |mut acc, &step| {
*acc.entry(step).or_insert(0) += 1;
acc
});
let error_rate = if total > 0 {
(distance as f64 / total as f64) * 100.0
} else {
0.0
};
HashMap::from([
("wer".to_string(), error_rate),
("tot".to_string(), total as f64),
("mat".to_string(), *counter.get(&'e').unwrap_or(&0) as f64),
("sub".to_string(), *counter.get(&'s').unwrap_or(&0) as f64),
("del".to_string(), *counter.get(&'d').unwrap_or(&0) as f64),
("ins".to_string(), *counter.get(&'i').unwrap_or(&0) as f64),
])
}
fn main() {
println!("Enter the hypothesis sentence:");
let mut hyp = String::new();
io::stdin().read_line(&mut hyp).expect("Failed to read line");
let hyp = hyp.trim();
println!("Enter the reference sentence:");
let mut ref_str = String::new();
io::stdin().read_line(&mut ref_str).expect("Failed to read line");
let ref_str = ref_str.trim();
let cer_result = calculate_cer(ref_str, hyp);
let wer_result = calculate_wer(ref_str, hyp);
println!("CER Results: {:?}", cer_result);
println!("WER Results: {:?}", wer_result);
}

일단 오늘 해보면서 느낀점은
- Copilot 보단 클로드가 코딩을 훨씬 잘한다. 그래도 결국 자꾸 틀린 부분을 찾아내고, 보완해주어야 하는 점을 구체적으로 지적하고 레퍼런스를 제공해야만 원하는 지점에 도달할 수 있다.
- 생각했던 것보다 Rust 구현체가 간결하고 직관적인게 python과 겹쳐보이는 구석이 있다.
오늘은 생각보다 너무 길어져서.. 다음에는 이 완성된 코드를 뜯어보며 변수의 형 정의나 특정 메서드들에 대해 공부해봐야겠다.