
기록하는삶
[논문 리뷰] Transformer _ 워드 임베딩(Word Embedding), 어텐션, 셀프 어텐션(Self-Attention) 이해하기 본문
[논문 리뷰] Transformer _ 워드 임베딩(Word Embedding), 어텐션, 셀프 어텐션(Self-Attention) 이해하기
mingchin 2022. 2. 4. 12:142017년 Attention is All you need 라는 이름으로 공개된 Transformer에 대해 공부하기 시작했는데, 정말 많은 사전 지식이 필요하다는 느낌을 받는다. 이전의 기계 번역의 과정과 문제점, 2016년 Attention의 활용에 대한 연구, 그것을 바탕으로 한 Transformer의 아이디어를 이해해보기 위해 꼭 이해해야하는 워드 임베딩과 어텐션의 개념을 정리해본다.
1) 워드 임베딩(Word Embedding)
기계가 자연어를 이해하기 위해서는, 당연히 우리가 사용하는 문자가 숫자로 바뀌는 과정, 즉 벡터화가 필요하다. 가장 단순하게는 원핫인코딩과 BOW(Bag of Words)로부터 각 단어를 맵핑하는 정수 인코딩 등의 방법이 있다.
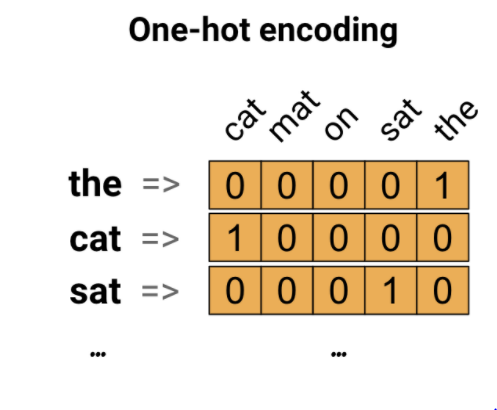
원핫인코딩은 서로 다른 단어의 수 만큼 그 차원이 필요하며, 자기 자신 외에는 모든 차원을 0으로 채운다는 점에서 매우 비효율적이며, 정수인코딩의 경우 해당 문제는 해결할 수 있지만, 각 단어의 정수화가 임의적이어서 단어간 유사도를 전혀 표현할 수 없다는 단점이 있다. 이러한 단점을 보완한 방법이 바로 워드 임베딩이다.

워드임베딩은 신경망을 통해 문장들을 학습하면서, 해당 문장들이 가진 모든 단어들을 고정된 차원의 벡터로 맵핑하는 방식을 따른다. Glove, FastText, Word2vec 등 다양한 방법론들이 존재하는데, 방법론에 따라 그 의미는 조금씩 다르지만 결국 '각 단어들이 얼마나 서로 관련이 있는가'가 벡터의 숫자로 표현된다는 것이 핵심이다. 대표적으로 Word2vec의 경우 특정 window_size 내에서 얼마나 빈번하게 단어들이 함께 등장하는가를 기준으로 단어들을 벡터화한다. 즉, 함께 등장한 횟수가 많은 단어들일수록 보다 유사한 벡터로 표현된다.
단어 간 유사도를 파악할 수 있고 단어의 수에 비해 훨씬 축소된 차원의 벡터로 맵핑하는 효율적인 방법이긴 하지만, 동음이의어의 구분이 어렵고 효과적인 맵핑을 위해서는 큰 데이터 셋을 활용한 충분한 학습이 필요하다는 등의 단점이 있다.
2) 어텐션(Attention), Self-Attention
크게 보면 인간의 집중, 주의 현상을 컴퓨터가 따라할 수 있도록 하는 신경망적 기법을 말한다. 'The cat sat on the mat' 이라는 문장을 읽는다고 하자. 읽는 과정을 자세히 살펴보면, sat이라는 단어를 읽을 때에는 '누가', '어디에', '어떻게' 앉는지가 문맥상 중요한 내용이기에, 앞 뒤의 the 보다는 cat, on, mat에 더욱 주의(Attention)를 기울이게 될 것임을 직관적으로 이해할 수 있다. 이러한 과정을 신경망을 통해 구현하고자 한 것이 Attention 기법이다.
Attention 기법의 핵심은 1차로 임베딩한 벡터들을 reweighing하여, 보다 문맥과 주의가 반영된 새로운 임베딩 벡터를 만들어내는 것이다. 즉, 어떻게 reweighing하면 어떤 단어들에 주의를 기울여야하는지가 포함된 벡터가 만들어질까를 알아내야한다.
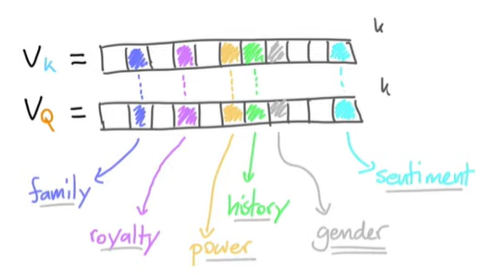
워드 임베딩의 기본 가정은, 위의 예시처럼 임베딩된 벡터의 각 차원들이 일종의 '의미'를 가져 유사한 의미를 가지는 단어들은 유사한 벡터로 표현될 것이라는 점이다. Self-Attention 기법은 이를 활용해 reweighing weights들을 탐색한다.

v1~v4는 임베딩된 벡터이고, 우리는 일련의 과정을 통해 보다 문맥적 의미를 가진 y1~y4의 임베딩 벡터를 만들어내는 것이 목적이다. 이때 위의 예시처럼 각 v1~v4의 차원마다 특정 의미가 있을 것이고, 주의를 기울여야 할 단어들 간에는 각 차원마다의 유사성이 있을 것이라는 가정 하에 v1~v4 각각에 자기 자신을 포함한 모든 단어들을 내적한 결과를 구한 뒤, softmax를 통과시켜 일종의 확률로 표현한다. (w_1i의 총합은 1이 될 것이다.) 이때 위 사진의 예시에서는, v1과 관련이 있을수록 w_1i의 값이 크게 표현될 것이다. 이렇게 구한 w_1i들과 v1~v4를 이용해 y1을 구하면, 다른 모든 벡터들의 영향력이 반영된 새로운 임베딩 벡터가 만들어지게 된다.
이러한 방법을 활용해,
1) weight를 학습하지 않고
2) 순서에 영향을 받지 않으며
3) 단어 간 거리에 영향을 받지 않고
4) 문장 길이에 구애받지 않는
방법으로 reweighing된 인코딩 벡터를 찾을 수 있다.
이러한 과정에 모델이 학습할 수 있는 가중치를 non-biased linear layer를 통해 추가하면 Self-Attention block이 완성된다.
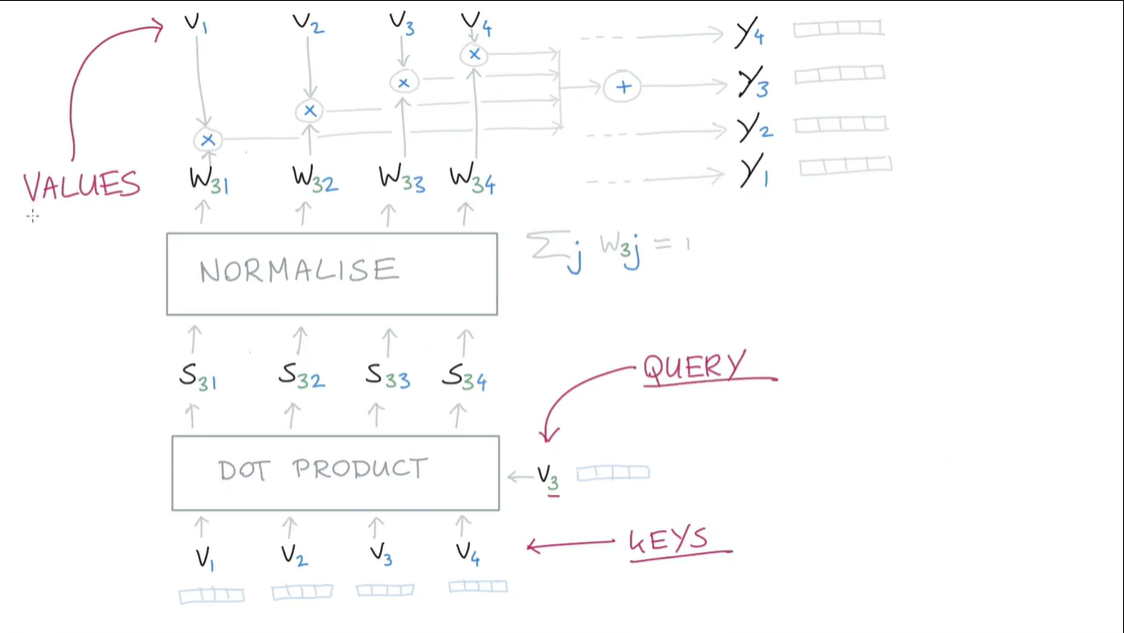

실제로는 아래 그림처럼 각 임베딩 벡터는 Key, Query, Value vector를 만들어내기 위한 Non-biased linear layer를 통과하는 구조이며, backpropagation을 이용해 업데이트 하는 방식으로 Key, Query, Value vector를 만들어내는 과정 자체를 학습할 수 있다.
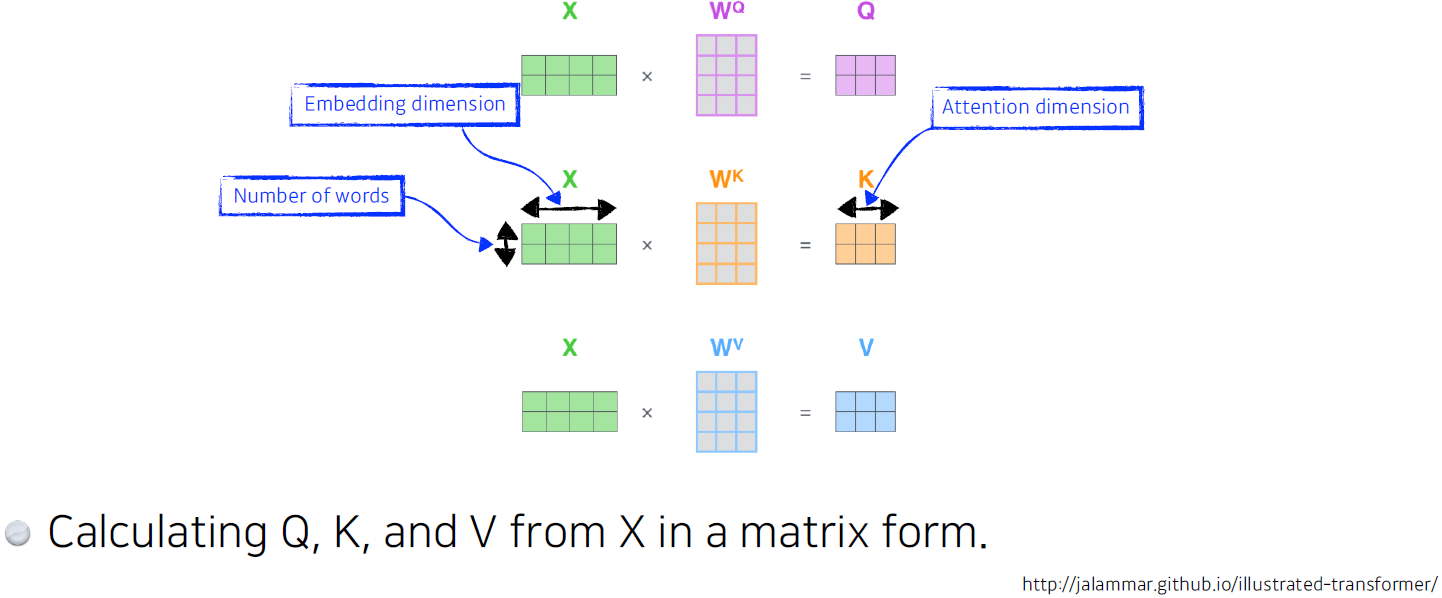

Tranformer에 활용된 기법은 이러한 Self-Attention 기법을 바탕으로 만들어진 Multi-head Attention 기법이다. 갈길이 멀구나^
참고자료:
① https://youtu.be/yGTUuEx3GkA
② https://youtu.be/tIvKXrEDMhk