
기록하는삶
[딥러닝/DL Basic] CNN (2) _ CNN의 변화와 발전(2012 ~ 2017) 본문
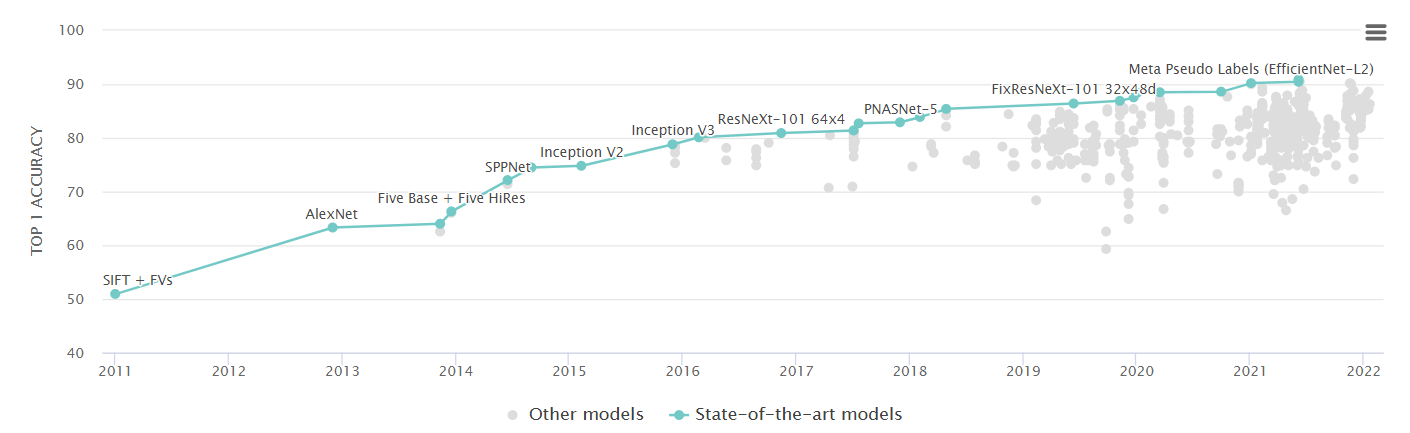
1000개 카테고리의 이미지에 대해 머신러닝을 활용한 Classification/Detection/Localization/Segmentation 성능을 비교하는 대회인 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)는 매년 가장 우수한 성능을 보인 모델을 선정한다. 이 글에서는 시기별로 해당 대회에서, 그 중에서도 Classification에 대해 우수한 성적을 보이며 이름을 알린 모델들을 간략하게 살펴보며, CNN이 어떻게 변화하고 발전해왔는지 아주 대략적으로 살펴본다. (추후에 하나씩 자세히 공부해 볼 가치가 있는 논문/모델들이다.)
1) AlexNet(2012)

먼저 AlexNet이다. 기본적인 아키텍쳐는 위와 같이 5개의 convolutional layer와 3개의 dense layer로 구성돼있다. 약 6000만개의 파라미터를 필요로하며, 핵심이 되는 키워드를 중심으로 정리하면 아래와 같다. 강의자가 정리하기를, 이제는 너무 당연한 것들로 자리잡은 것들이 처음 검증된 사례라고 할 수 있다고 했다.
① Rectified Linear Unit(ReLU) activation
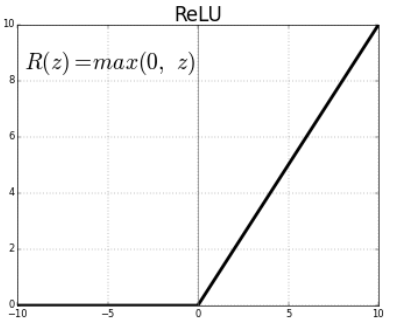
활성화 함수로 Relu를 사용했다. 모델의 선형성을 유지하면서, 보다 좋은 generalization performence를 보이고, sigmoid와 hyperbolic tangent에서 발생하는 기울기 소실 문제(gradient vaniching problem)를 해결해줄 수 있다. Relu를 사용했을 때 발생할 수 있는 'Lateral inhibitation' 문제를 해결하기 위해 Local Response Normalization(LRN)을 활용하기도 했다.
② GPU implementation(2 GPUs)
알종에 multi-gpu가 사용된 사례다. 위 모델의 아키텍쳐의 보면 하나의 input에 대해 11*11 kernel을 2개 사용하고, parallel하게 연산이 진행되도록 설계된 것을 볼 수 있다. 이미지를 둘로 나누어 반씩 학습/예측하는 것인데, 이 당시에는 GPU 성능이 부족해 물리적으로 연산을 진행할 수 없었기 때문에 저런 시도가 있었다고 한다. 자세히 보면 병렬적 연산을 진행하되 서로 교차되며 연결되기도 하는데, 이러한 과정은 GPU의 성능이 향상되면서 더이상 필요하지 않기 때문에 생략한다.
③ Overlapping pooling
AlexNet과 유사한 구조를 가졌던 LeNet-5가 stride=1인 2*2 average pooling을 사용한 것과 달리, stride=2인 3*3 max pooling을 사용, Overlapping pooling을 함으로써 성능을 향상시켰다고 한다.
④ Data augmentation
이미지의 특정 부분을 잘라내는 crop과 이를 이용한 회전, 대칭 등을 통해 Label-preserving transformation을 실시한 이미지들을 추가로 학습에 사용했다.
⑤ dropout
첫 3개의 dense layer 중 2개의 p=0.5의 dropout을 적용했다.
실제 AlexNet이 대회를 우승한 이후로는 매해 딥러닝 모델들이 우승을 차지했고, AlexNet이 제안했던 위 방식들의 장점을 살리고 단점은 보완하는 방식으로 추후의 모델들이 발전해나갔다.
2) VGGNet(2014)
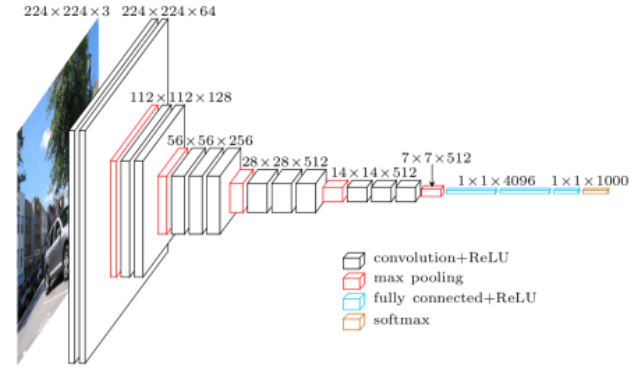
VGGNet의 가장 큰 특징이라면 1억개가 넘어가는 엄청난 파라미터 수를 자랑한다는 점과, 3*3 kernel만을 반복해 사용하는 factorizing convolution을 사용했다는 점이다.
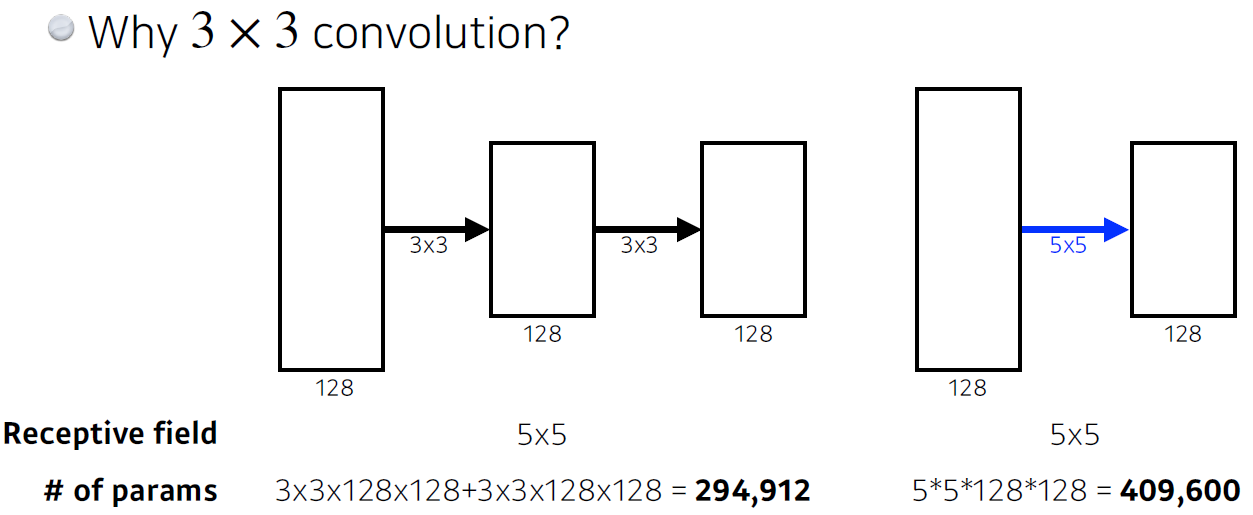
Receptive field는 output의 한 노드(픽셀)에 영향을 미치는 input의 공간 크기(와 위치)를 말하는데, 위 그림처럼 3*3 convolution을 두 번 연달아 하는 것과 5*5 convolution을 한 번 하는 것은 output feature map의 모든 픽셀들이 동일한 Receptive field를 갖게 하는 연산이다. 쉽게 말해 '거의 유사한 연산'이라 할 수 있는데, 사용되는 파라미터의 수는 꽤 큰 차이를 보이게 된다. 이러한 이유로 AlexNet이 11*11, 5*5 kernel 등을 사용한 것과 달리 VGGNet은 3*3 kernel만을 사용하는 모델을 구축했다. (다만 이러한 3*3 kernel만을 사용해도 layer의 수가 특정 개수를 초과하면 의미가 없다는 것이 밝혀지면서, 이후 논문들에서는 다른 방법으로 성능을 향상하고자 했다고 한다.)
3) GoogLeNet(2014)

다음은 VGGNet을 제치고 2014년 1위를 차지했던 GoogLeNet이다. 대회에 사용된 모델은 inception v1이고, 이후 2015년 논문에서 공개된 것은 수정 보완한 inception v2라고 한다. 위 아키텍쳐에서 알 수 있듯 비슷한 모양의 network가 반복된다고 해서 NiN(Network in Network) 구조라고 칭한다. 핵심은 이름에서 알 수 있는 것처럼, 아래 구조의 inception block이다.

GoogLeNet에서 반복 사용된 inception block은 크게 두 가지 의미에서 중요하다.
① 하나의 input에 대해 서로 다른 4개의 receptive field를 갖는 필터를 활용해 연산을 진행한 후 concatenation을 하기 때문에 여러 response들을 한데 모을 수 있다.
② 1*1 convolution을 사용함으로써 파라미터의 수를 현저히 줄일 수 있다. (그 이유는 이전 글 참고)
이러한 구조 덕분에, AlexNet의 12분의 1 정도밖에 되지 않는 약 5백만 개의 파라미터 만으로 훌륭한 성능을 내는 모델이 만들어졌다.
4) ResNet(2015)
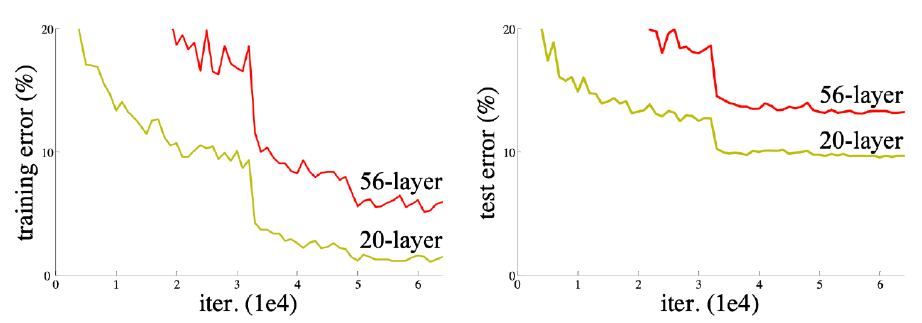
ResNet의 등장이 가지는 가장 큰 의의는 layer를 깊게 쌓았을 때 학습이 어려워지는 문제를 해결할 가능성을 제시했다는 점이다. layer가 깊어질수록(약 20개를 넘어가면) over-fitting은 커녕 layer의 개수가 적을 때보다 training error조차 낮아지기가 어려운 문제가 있었는데, identity map(skip connection)이 그 장벽을 뛰어넘을 수 있는 도구로 제안되었다.
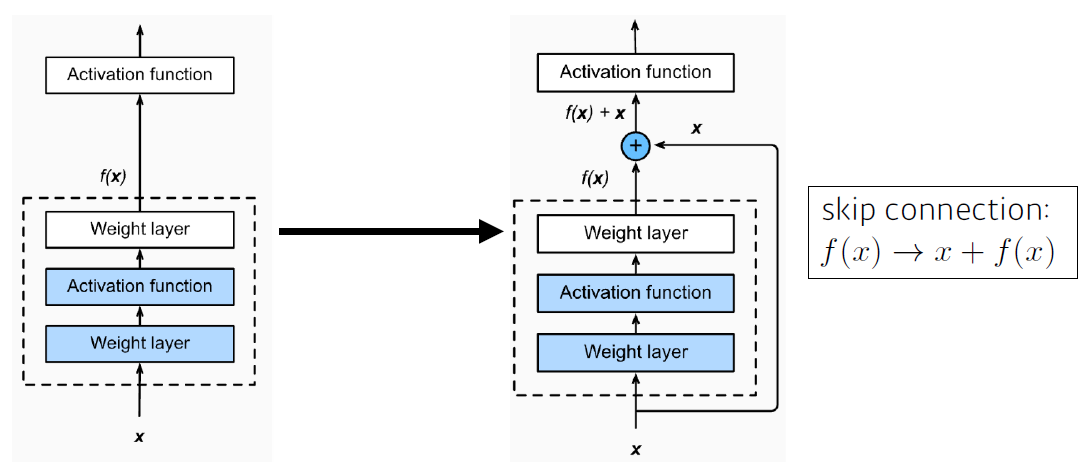
그림처럼 특정 시점의 input에 대해 layer를 통과한 ouput과 input을 더해줌으로써 해당 layer가 input과 output의 차이(residual)를 줄이는 방향으로 학습하도록 하는 방법이다. ResNet 연구팀은 이러한 방법을 적용하면 아래와 같이 layer의 수가 더 많아지더라도 학습 성능이 개선됨을 확인했다고 한다.

또한 아래 구조처럼 1*1 convolution을 3*3 convolution 앞뒤에 적절히 활용하여 파라미터 수를 줄이고, skip connection을 위한 channel의 수를 조절하는 bottleneck 구조 역시 제안되었고 한다.

5) DenseNet(2017)
ResNet과 유사하지만, skip connection이 ouput과 input을 더해주는 방식이었다면, DenseNet에서는 concatenate 해주는 방법으로 skip connection을 구현했다는 점이 다르다.
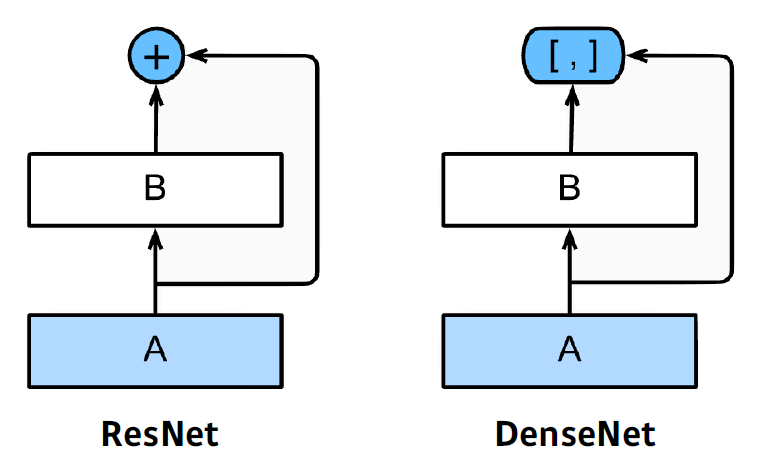

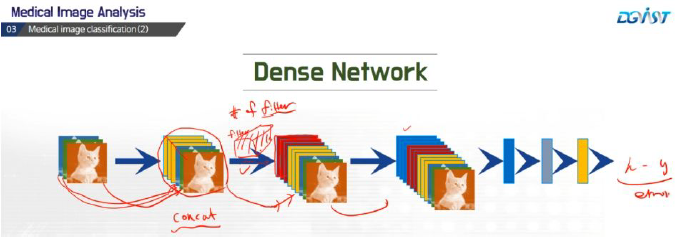
Dense block에서 이전에 존재했던 모든 피처맵들을 이후의 피처맵에 그대로 연결한다는 것이 특징이며, 이렇게 하면 channel의 수가 2의 거듭제곱으로 빠르게 증가하는 문제를 Transition Block에서 1*1 covolution과 BatchNormalization을 통해 차원을 축소하여 해결하는 것을 반복하는게 그 특징이다.
6) Summary
정말 간략하게 AlexNet ~ DenseNet의 큰 흐름만을 살펴보았다. 하나하나 자세히 살펴보면 공부할 것들이 너무나도 많지만, CNN에서 성능을 향상시키기 위한 중요한 발전 방향성은 아래와 같이 정리해볼 수 있다.
① 잘라내기, 회전, 반전, 노이즈 삽입 등을 통한 Data agmentation으로 더 많은 학습 데이터 확보
② 3*3 kernel의 반복된 사용과 1*1 kernel의 적절한 사용 등을 통해 파라미터의 수를 줄여나가기
-> 파라미터의 수가 적을수록 generalization performance가 좋고, 학습 속도와 메모리 면에서 효율이 좋다.
③ addition, concatenation 등을 활용해 더 깊은 layer를 쌓아도 모델이 잘 작동하도록 함
이후에는 Transformer가 등장하면서 CNN에도 큰 영향을 준 것으로 알고 있는데, 이는 추후에 더 정리해보도록 하겠다.
'AI > DL Basic' 카테고리의 다른 글
| [딥러닝/DL Basic] 딥러닝의 Key components 4가지 (0) | 2022.02.11 |
|---|---|
| [딥러닝/DL Basic] CNN (1) _ 기초 개념 및 용어 정리 (0) | 2022.02.08 |
| [딥러닝/DL Basic] 최적화(Optimization) 관련 용어 정리 (3) _ Regularization (0) | 2022.02.08 |
| [딥러닝/DL Basic] 최적화(Optimization) 관련 용어 정리 (2) _ Gradient_decent methods (0) | 2022.02.07 |
| [딥러닝/DL Basic] 최적화(Optimization) 관련 용어 정리 (1) (0) | 2022.02.07 |



