
기록하는삶
[논문 리뷰] Item-based Collaborative Filtering Recommendation Algorithms, 아이템 기반 협업 필터링 본문
[논문 리뷰] Item-based Collaborative Filtering Recommendation Algorithms, 아이템 기반 협업 필터링
mingchin 2022. 2. 20. 03:00추천시스템의 핵심 과제는 질 좋은 추천을 제공하고, 초당 더 많은 추천을 제공하고, 데이터의 희소성(sparsity)이 있더라도 성공적으로 추천이 가능하도록 하는 것이다. 이 논문이 발행된 2010년을 기준으로 해당 시점까지 가장 각광받던 기술은 협업필터링(collaborative filtering)인데, 이는 기존 유저들의 데이터베이스를 바탕으로 신규 유저와 비슷한 유저가 좋아했던 상품을 신규 유저도 좋아할 것이라는 것을 전제로 추천하는 방법론이다. 이 논문 이전에 주를 이뤘던 방법으로는 유저의 직접적인 의견을 바탕으로 협업필터링 기법을 적용한 Tapestry, decision tree 기반의 Bayesian networks, 비슷한 유저를 묶는 Clustering, 유저를 node로 유저간 유사도를 edge로 표현하는 그래프 기반 기술인 Horting 등이 있다. 이들을 포함한 이전의 방법론들은 아래 2가지 과제를 극복해야만 했다.
① 확장성(scalability)
유저간 유사성을 파악한다는 것은 유저의 수가 늘어날수록 연산 상의 부담으로 작용하게 된다. 예를 들어 특정 웹사이트에서 browsing pattern을 상품 선호도 파악을 위해 사용한다면, 한 유저당 사용해야하는 데이터의 양이 많아지면서 비슷한 유저를 찾는데 걸리는 시간이 크게 늘어나게 될 것이다.
② 추천의 질 향상(improve the quality of the recommendations for users)
자신의 취향에 맞지 않는 추천이 계속된다면, 유저들이 이를 거부하기 시작할 것이므로 유저들에게 상품 추천이 신뢰할 수 있다는 느낌을 주어야한다.
①, ②는 일종의 trade-off 관계에 놓이게 되는데, 이를 동시에 해결하는 방법론으로 유저간 유사도가 아닌 상품간 유사도에 기반하는 협업 필터링 기법을 제시하는 것이 이 논문이다.
0) Overview of the Collaborative Filtering Process
협업 필터링 알고리즘의 목표는 새로운 상품을 추천하고, 특정 아이템에 대한 특정 유저의 유용성 평가를 예측하는데 있다. 이는 기존의 유저들의 상품에 대한 opinion을 기반으로 하는데, explicit하게 드러나는 rating-score부터 implicit하게 드러나는 purchase record, timing logs, web hyperlinks 등이 이에 해당한다. 알고리즘의 대상이 되는 유저를 active user라 칭하며, active user에게 아래의 두 가지, active user가 사용(구매)하지 않은 아이템에 대한 선호도 예측과 N개의 상품 추천을 제공하는 것이 목표이다.


이러한 협업 필터링 방법론은 크게 entire user-item database로부터 active user와 유사한 유저의 그룹인 neighbors를 찾아내는 Memory-based(or user-based)와 Bayesian networks, Clustering, Rule-based 등에 기반한 머신러닝 알고리즘을 적용해 user ratings의 모델을 만들고 이에 기반해 상품을 추천하는 Model-based 방법으로 나뉜다. 해당 논문은 기존에 많이 사용되던 user-based 방법론의 경우 전체 상품에 비해 유저들이 사용하는 상품의 수가 너무 적을 수밖에 없고(Sparsity), 유저의 수와 상품의 수가 늘어날수록 알고리즘의 연산 부담이 급격하게 늘어난다는 문제(Scalability)를 해결하고자 Model-based 방법론인 item-based appraoch를 소개하고 있다. 이 접근은 유저가 이전에 구매한 상품과 유사한 상품은 선호하고, 이전에 좋아하지 않았던 상품과 유사한 상품은 기피할 것이라는 점을 전제로 한다.
0) Data set
1997년 공개된 MovieLens의 데이터가 활용됐다. MovieLens는 웹 기반 추천 시스템 및 가상 커뮤니티로, 이 곳을 방문해 영화를 평가하고 추천받는 사람들의 데이터가 축적되는 곳이다. 10만 개의 평가를 얻어내기 위해 유저들을 랜덤하게 선정하였고, 이 과정에서 20개 이상의 영화를 평가한 유저만 활용했다고 한다.
0) Evaluation Metrics
① Statistical accuracy metrics
특정 유저의 상품 i에 대한 평가에 대한 예측에 대한 지표로써 MAE(Mean Absolute Error)를 활용했다.

논문에 따르면 RMSE와 Correlation 역시 보조적으로 연구에 활용된 것 같긴한데, 이에 대한 구체적 수치 언급은 찾아보기 어렵다.
② Decision support accuracy metrics
상품 추천이 유저에게 도움이 되었는지를 평가하는 지표로써, 추천이 잘 되었는지 여부를 binary operation으로 가정하였다(good or bad). 이 지표를 평가하기 위해 주로 사용되는 metric은 reversal rate, weighted errors and ROC sensitivity라 논문은 언급하는데, 그 아래의 언급을 보면 아마도 ROC를 활용한 것 같다. 지난 연구에서 MAE와 ROC가 유사한 기능을 함을 밝혔기에, 해당 논문에서는 MAE를 평가 지표로 활용했다.

1) Item Similarity Computation
user-based 방법론과 달리 target user의 특정 상품 i에 대한 선호도를 파악하기 위해, 해당 target user가 이미 평가한 다른 k개의 상품과 i와의 유사도를 계산하고, 이를 바탕으로 i에 대한 선호도를 예측한다. 상품간 유사도 계산 방법으로는 아래 세 가지가 제안되었는데, 이중 가장 좋은 성능을 보인 것은 adjusted cosine이었다.
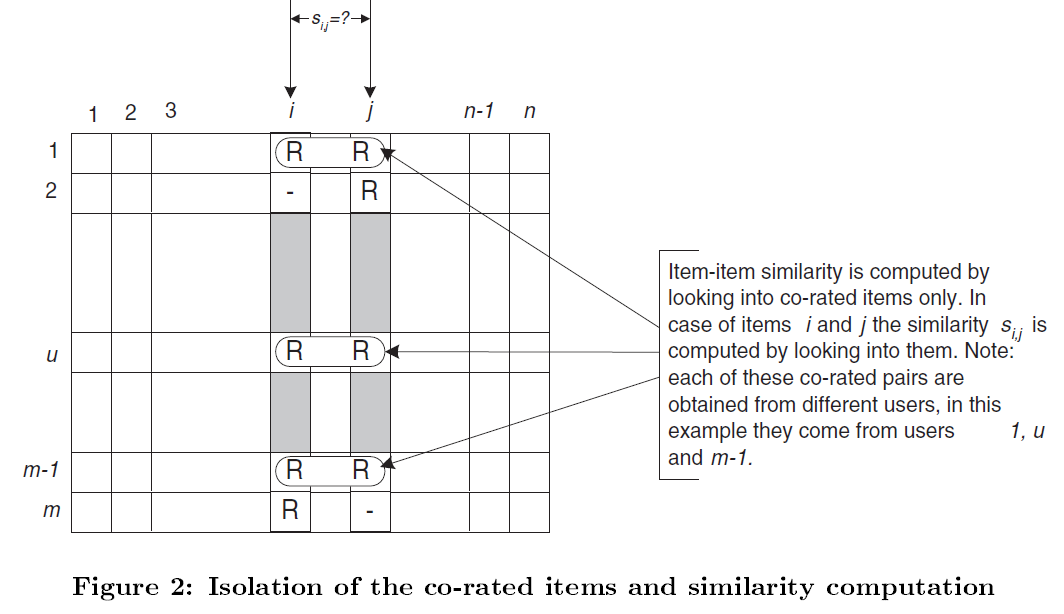
상품 i와 j의 유사도 계산시에는 위처럼 i, j에 대해 모두 평가한 유저의 정보만을 사용하게 된다.
① Cosine-based Similarity
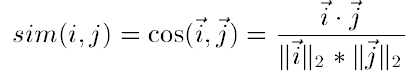
② Correlation-based Similarity

③ Adjusted Cosine Similarity

유저에 따라 대체로 평가를 좋게 주거나 나쁘게 주는 경우가 있을 수 있다. 각 유저의 평균 rating을 연산에 사용함으로써 다른 두 방법이 유저마다 다른 rating scale을 고려하지 못한다는 점을 보완한 방법이다. 실제 논문에서도 ③의 방법을 사용하였다.

2) Prediction Computation
target user의 상품 i에 대한 선호도 예측을 위해 i와 다른 상품 k개의 유사도를 구했다면, 이제 이를 이용해 예측치(선호도)를 계산해야한다. 논문에서는 두 가지 방법을 소개하며 그 성능을 비교한다.
① Weighted Sum
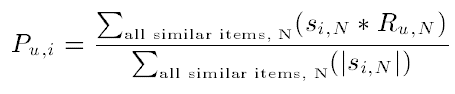
s_i,N은 상품 i와 N간의 유사도, R_u,N은 유저 u의 상품 N에 대한 평가(rating)를 말한다.
② Regression

Weighted Sum과 동일한 산식을 사용하되, 유저의 평가인 R_u,N을 직접 사용하는 대신 위와 같은 산식으로 그것을 대체하는 방법이다. 이는 두 상품에 대한 벡터가 유클리드 거리는 멀지만 유사도가 높게 나오는 경우, 예측 정확도가 떨어질 수 있음을 고려한 방법이라고 논문은 소개한다.
3) Performance Implications
사용자 수가 많은 E-Commerce sites의 경우 이미 당시 user-based CF system을 실시간으로 적용해 상품을 추천하기에 병목현상이 발생하는 상황이었다. 또한 유저의 수나 성향 등은 상대적으로 static한 정보가 아니라는 점도 문제가 될 수 있다. 상품의 정보는 이에 반해 static한 정보에 가까우며, 이를 활용해 상품 간의 관계는 미리 계산(precompute)할 수 있다는 것이 큰 장점이다. 다만 n개의 상품에 대해 상품 유사도를 모두 사전에 계산한 뒤, 실제 모델에서는 quick table look-up을 통해 이를 가져오는 방식을 채택한다 하더라도, 시간은 절약되지만 O(n**2)의 공간 복잡도를 요한다는 문제가 남아있다.
이를 해결하기 위한 방안이 model size(=k)이다. 이는 특정 아이템 x와 다른 아이템 간의 유사도 중 상위 k개만 사용하는 방법이다. 당연히 model size를 줄이는 것과 예측의 quality performance는 trade-off 관계에 놓이게 되지만, 논문은 연구를 통해 아주 작은 모델 사이즈 만으로도 충분히 훌륭한 예측이 가능함을 확인했다고 밝히고 있다.
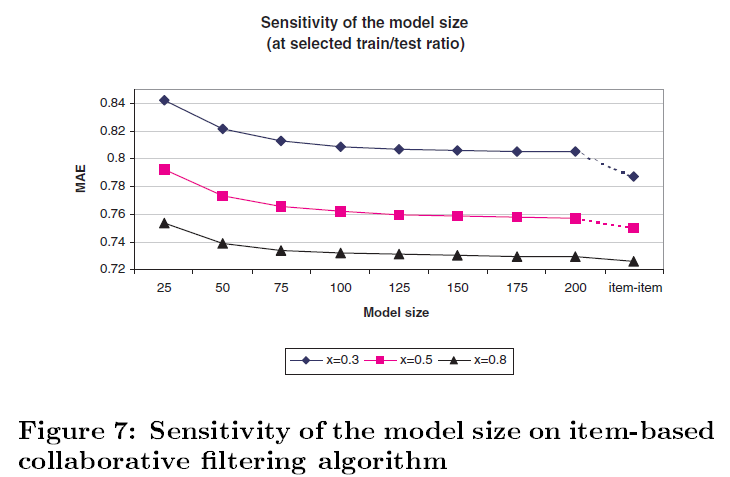
전체 데이터 중 80%를 학습에 사용한 경우에 한해 모델 사이즈를 각각 전체 상품 수의 1.9%와 3%로 설정했을 때, 전체 아이템을 사용했을 때 정확도의 96%와 98.3% 만큼의 정확도를 보였다고 한다.
4) Experimental Results
외에 논문이 제시하는 연구 결과들을 살펴보면, data sparity level(데이터가 부족한 정도)에 따라 어떠한 성능을 보이는지 평가하기 위해 train-test dataset의 비율을 조정하거나, 참조하는 이웃의 수(neighborhood size)를 조정해가며 성능을 비교하고, 위의 조건들을 같게 하였을 때 user-based CF와의 성능을 비교한 것을 확인할 수 있다. 이때 비교 대상으로는 Pearson nearest neighbor algorithm을 본인들이 튜닝하여 사용했다고 한다.


연구 결과를 요약하면 아래와 같다.
① 모든 sparsity level에서 user-based CF 보다 item-based CF가 우수한 성능을 보였다.
② 보다 sparse한 데이터셋에 한해서는(데이터의 양이 부족할 때, x가 작을 때) regression-based 모델이 단순 weighted sum을 활용한 모델보다 더 우수한 성능을 보였지만, 데이터의 양이 많아질수록 반대의 경향을 보였다.
③ 이 논문의 저자들은 전체 데이터의 80%를 학습에 활용할 때(x=0.8)가 가장 omptimal하다고 판단했다.
④ 단순 weighted sum을 활용한 모델의 경우 neighborhood size가 10에서 30까지 증가할 때 그 성능 향상이 급격히 이루어지는 데 반해 regression-based 모델의 경우 neighborhood size가 커질수록 오히려 성능이 조금씩 악화된다는 점을 고려해, neighborhood size=30이 optimal value라고 판단했다. (여기서 neighborhood size란 아이템 i에 대한 유사도를 구할 때 몇 명의 유저를 참고할 것이냐를 말하는 것 같은데, 이 부분이 약간 모호하다. 30이라 치면 어떤 기준으로 30명을 고르지?)
5) Discussion / Conclusion
이 논문의 결론과 의의를 정리해보면 다음과 같다.
① user-based CF보다 item-based CF가 하이퍼 파라미터(neighborhood size, training/test ratio)의 변화와 관계 없이 일관적으로 더 우수하다. 다만 그 차이가 눈에 띄게 크지는 않다.
② 상품 간의 관계는 유저 간의 관계보다 static하며, 이는 그 관계성에 대한 pre-computation이 가능할 것이라는 점을 시사한다. 이는 방대한 양의 데이터를 빠르게 다뤄야하는 online에서 우수한 성과를 보일 것이다.
③ 3)에서 언급한 것처럼, 아주 적은 양의 데이터만으로도 꽤 훌륭한 예측이 가능함을 확인하였다.
'논문 스터디' 카테고리의 다른 글
| [논문 리뷰] Qwen3-ASR (1) | 2026.03.11 |
|---|