
기록하는삶
[협업/MLOps] 머신러닝 실험, 배포를 위한 오픈소스 MLflow 본문
MLflow - A platform for the machine learning lifecycle
An open source platform for the end-to-end machine learning lifecycle
mlflow.org
MLflow는 머신러닝 실험을 보다 쉽고 효율적으로 진행하며 관련된 로그와 파일을 저장하고, 이를 공유해 협업하거나 배포할 수 있는 장치를 제공하는 오픈소스다. MLflow는 기존의 머신러닝 실험이 추적하기 어렵고, 코드를 재현하기 어려우며, 모델을 패키징하고 배포하는 방법이 어렵고, 모델을 관리하기 위한 중앙 저장소가 없다는 문제를 해결하기 위해 만들어졌으며, 2018년 출시 이후 이용자 수가 빠르게 늘며 가파른 성장을 보이고 있다. CLI와 GUI를 모두 지원하며, 아래의 핵심 기능과 components들을 가진다.
① 핵심 기능
1) Experiment Management & Tracking
- 머신러닝 관련 “실험”들을 관리하고, 각 실험의 내용들을 기록
- 여러 사람이 하나의 MLflow 서버 위에서 각자 자기 실험을 만들고 공유 가능
- 실험을 정의하고, 실험을 실행할 수 있음. 이 실행은 머신러닝 훈련 코드를 실행한 기록
- 각 실행에 사용한 소스 코드, 하이퍼 파라미터, Metric, 부산물(모델 Artifact, Chart Image) 등을 저장
2) Model Registry
- MLflow로 실행한 머신러닝 모델을 Model Registry(모델 저장소)에 등록 가능
- 모델이 저장될 때마다 해당 모델에 버전이 자동으로 올라감(Version 1 -> 2 -> 3..). 이를 이용한 버전 관리 가능
- Model Registry에 등록된 모델은 다른 사람들에게 보다 쉽게 공유 가능하고, 활용할 수 있음
3) Model Serving
- Model Registry에 등록한 모델을 REST API 형태의 서버로 Serving 할 수 있음
- Input = Model의 Input
- Output = Model의 Output
- 직접 Docker Image를 만들지 않아도 생성할 수 있음
② MLflow Component
1) MLflow Tracking
- 머신러닝 코드 실행, 로깅을 위한 API, UI
- MLflow Tracking을 사용해 결과를 Local 혹은 Server에 기록해 여러 실행과 비교 가능
- 팀에선 다른 사용자의 결과와 비교하며 협업할 수 있음
2) MLflow Project
- 머신러닝 프로젝트 코드를 패키징하기 위한 표준이자 일종의 템플릿
- 소스 코드가 저장된 폴더
- Git Repo와 유사
- 의존성과 어떻게 실행해야 하는지 저장
- MLflow Tracking API를 사용하면 MLflow는 프로젝트 버전을 모든 파라미터와 자동으로 로깅
3) MLflow Model
- 모델은 모델 파일과 코드로 저장
- 다양한 플랫폼에 배포할 수 있는 여러가지 도구 제공
- MLflow Tracking API를 사용하면 MLflow는 자동으로 해당 프로젝트에 대한 내용을 사용함
4) MLflow Registry
- MLflow Model의 전체 Lifecycle에서 사용할 수 있는 중앙 모델 저장소
③ 사용 예시
set -xe \
&& apt-get update -y \
&& apt-get install - y python3-pip
# 혹은
sudo apt update
sudo apt install python3-pippip 설치가 되어있지 않은 경우 pip를 먼저 설치해준다.
pip install mlflow이후 mlflow를 설치한다.

다음과 같은 에러가 나서 이를 먼저 해결했다.
pip install click==7.1.2
pip install zipp==3.1.0가장 먼저는 실험(Experiment)을 생성한다. 하나의 Experiment는 진행하고 있는 머신러닝 프로젝트 단위로 구성하며, “개/고양이 이미지 분류 실험”, “택시 수요량 예측 분류 실험” 등이 그 예이다. 하나의 실험 내에서는 RMSE, MSE, MAE, Accuracy와 같이 정해진 Metric으로 모델을 평가하며, 여러 Run(실행)을 가질 수 있다.
# mlflow experiments create --experiment-name (실험이름)
mlflow experiments create --experiment-name my-first-experiment
ls -al로 확인해봤을 때 위와 같이 mlruns 폴더가 생성되면 성공적으로 실행된 것이다.
# 생성한 실험 목록 확인
mlflow experiments list
생성한 실험의 목록을 이렇게 확인할 수 있다.
이제 머신러닝 코드에 대해 mlflow가 일하도록 해보자. 아래처럼 autolog()를 실행시킨 뒤에 mlflow의 start_run() 안에서 학습을 시키면 자동으로 mlflow가 학습 과정 중 주요 사항을 기록한다.
mkdir example
vi example/train.py
===========================================================
# train.py
import numpy as np
from sklearn.linear_model import LogisticRegression
import mlflow
import mlflow.sklearn
if __name__ == "__main__":
mlflow.sklearn.autolog()
X = np.array([-2, -1, 0, 1, 2, 1]).reshape(-1,1)
y = np.array([0, 0, 1, 1, 1, 0])
solver = "saga"
penalty = "elasticnet"
l1_ratio = 0.1
lr = LogisticRegression(solver=solver, penalty=penalty, l1_ratio=l1_ratio)
with mlflow.start_run() as run:
lr.fit(X,y)
score = lr.score(X,y)
print(f"Score: {score}")다음으로는 프로젝트 생성을 해줘야한다. 프로젝트 파일은 패키지 모듈의 상단에 위치해야하며, MLflow를 사용한 코드의 프로젝트 메타 정보 저장하고 프로젝트를 어떤 환경에서 어떻게 실행시킬지 정의한다.
vi example/MLProject
===================================================
name: tutorial
extry_points:
main:
command: "python3 train.py"이제 mlflow를 활용해 학습 코드를 실행(Run)할 준비가 되었다. 하나의 Run은 코드를 1번 실행한 것을 의미하며, 보통 Run은 하나의 모델 학습 코드를 실행한다. 즉, 한번의 코드 실행마다 하나의 Run을 생성하며 아래의 내용들이 기록된다.
# --no-conda는 optional
$ mlflow run example --experiment-name my-first-experiment --no-conda
- Source : 실행한 Project의 이름
- Version : 실행 Hash
- Start & end time
- Parameters : 모델 파라미터
- Metrics : 모델의 평가 지표, Metric을 시각화할 수 있음
- Tags : 관련된 Tag
- Artifacts : 실행 과정에서 생기는 다양한 파일들(이미지, 모델 Pickle 등)
다음과 같이 실행되었다. 이제 결과를 gui로 살펴보자.
mlflow ui
이렇게 로컬 서버 주소를 받을 수 있다. 접속해보면,
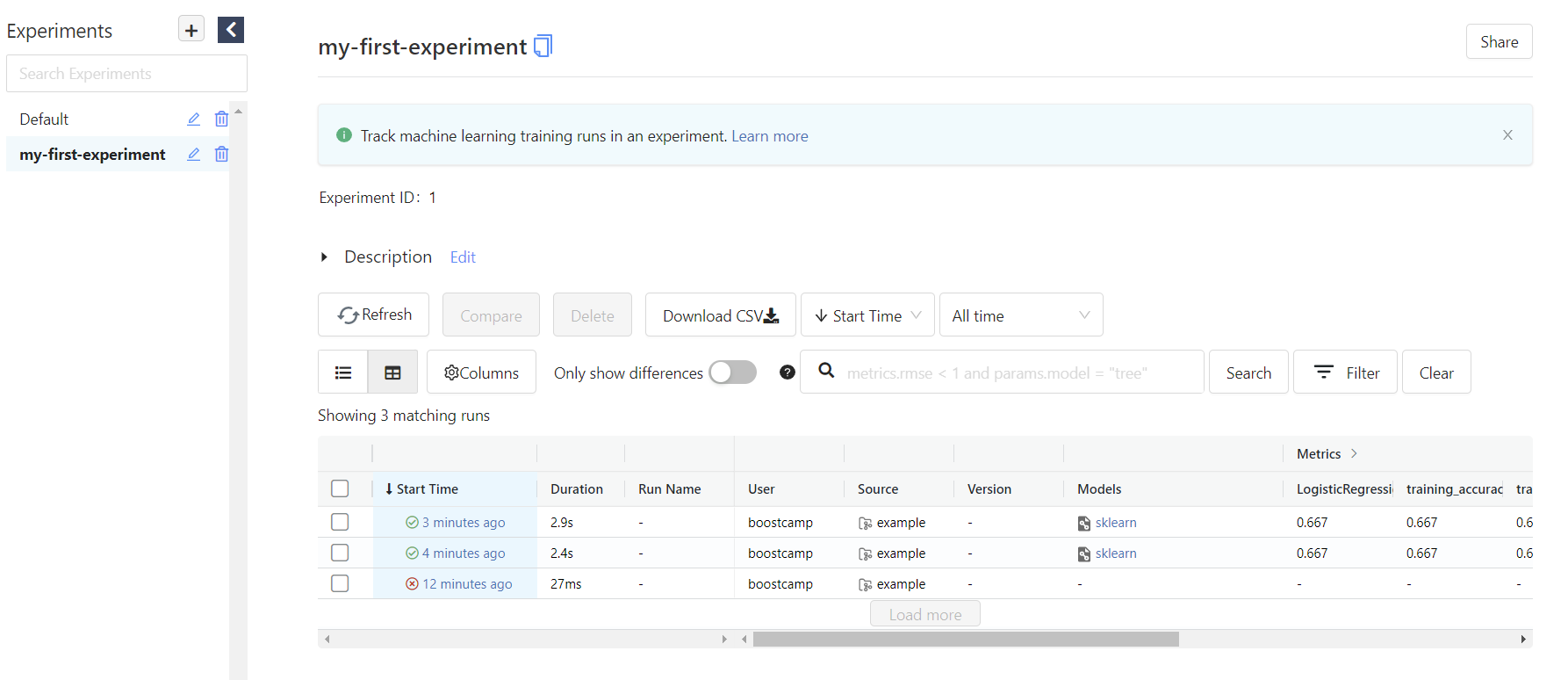
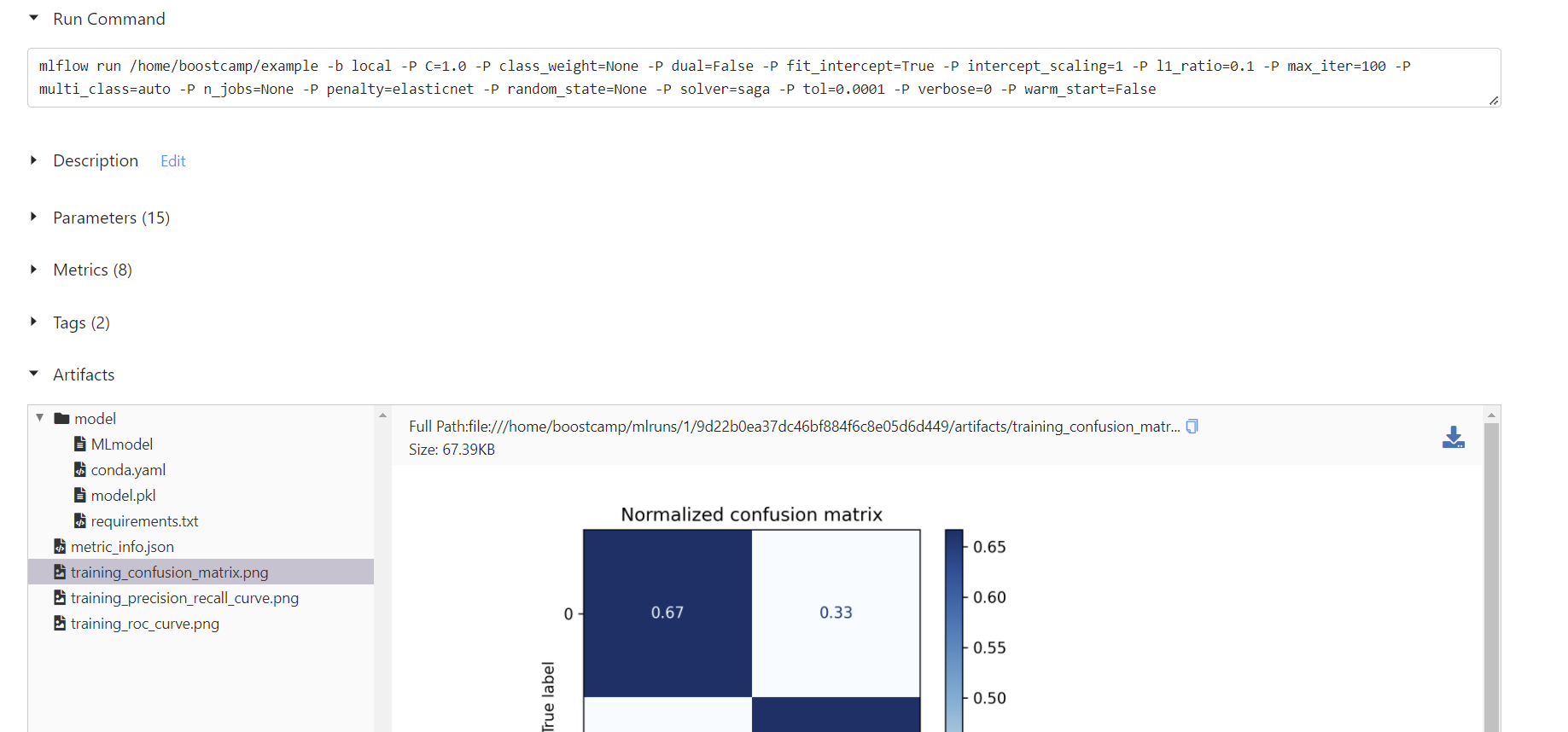
실패한 run을 포함한 실행 기록을 볼 수 있고, 각 실행으로 들어가면 Run command, Parameters, Metrics 등의 세부 지표를 볼 수 있고, autolog가 자동으로 저장한 모델 파일, requirements.txt, confusion matrix의 그래프 이미지, ROC curve 그래프 등을 포함한 artifacts들을 확인할 수 있다.
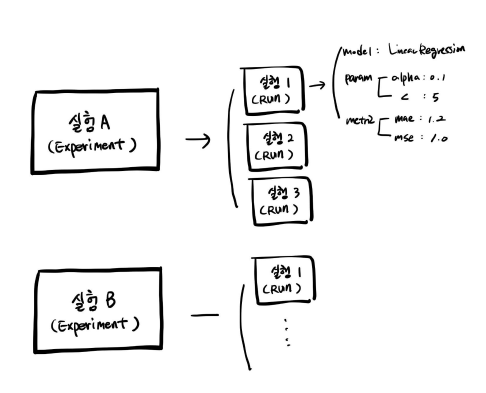
이처럼 하나의 실험(Experiment) 안에 여러 실행(Run)을 간편하게 관리하고 기록할 수 있다는 장점이 있다.
위 방법처럼 train.py 파일 내에서 파라미터들을 관리하는 것이 아니라, CLI Command에서 파라미터들을 던져주도록 하고 싶다면, train.py와 MLProject 파일, 그리고 명령어를 아래와 각각 아래와 같이 바꾸어주면 된다.
# train.py
import argparse
import sys
import numpy as np
from sklearn.linear_model import LogisticRegression
import mlflow
import mlflow.sklearn
if __name__ == "__main__":
mlflow.sklearn.autolog()
X = np.array([-2, -1, 0, 1, 2, 1]).reshape(-1,1)
y = np.array([0, 0, 1, 1, 1, 0])
lr = LogisticRegression(solver=sys.argv[1], penalty=sys.argv[2], l1_ratio=float(sys.argv[3]))
with mlflow.start_run() as run:
lr.fit(X,y)
score = lr.score(X,y)
print(f"Score: {score}")name: tutorial
entry_points:
main:
parameters:
solver:
type: string
default: "saga"
penalty:
type: string
default: "elasticnet"
l1_ratio:
type: float
default: 0.1
command: "python3 train.py {solver} {penalty} {l1_ratio}"mlflow run example -P solver="saga" -P penalty="elasticnet" -P l1_ratio=0.01 --experiment-name my-first-experiment --no-condadefault 값을 사용하고 싶다면 입력하지 않아도 되고, 다른 값을 주고 싶다면 직접 입력해주면 된다. 지금까지는 로컬 환경에서 mlflow를 이용하는 방법이었다면, sqlite 등의 DB를 활용해 서버를 공유하고 협업을 하는 방법도 있다. 다음 글에 정리해 보겠다,,
'AI > 개발환경' 카테고리의 다른 글
| [Poetry/협업] 가상 환경 및 의존성 관리 도구 (0) | 2022.05.25 |
|---|---|
| Unix 표준 스트림, Redirection & Pipe, 서버에서 자주 사용하는 쉘 커맨드(Shell Command) (0) | 2022.02.17 |
| 윈도우(Window) pycocotools 설치, pip install pycocotools (0) | 2022.02.15 |
| [협업/MLOps] Weights & Biases (0) | 2022.01.26 |
| [Jupyter notebook/주피터 노트북] 알아두면 유용한, 주피터 노트북 단축키 (0) | 2022.01.17 |



