기록하는삶
[파이토치/Pytorch] tensor 조작 기본 함수와 Self-Attention의 mask 생성 과정 이해하기 본문
[파이토치/Pytorch] tensor 조작 기본 함수와 Self-Attention의 mask 생성 과정 이해하기
mingchin 2022. 3. 28. 20:291) tensor의 data type
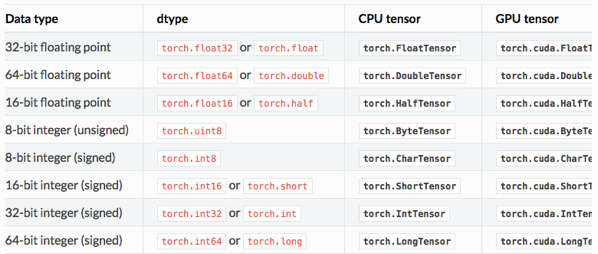
tensor에는 위와 같이 다양한 자료형이 있다.(사진은 왜 잘려있을까?) 자료형마다 필요로하는 메모리가 달라지기 때문에 최적화와 관련 있을 듯 한데, double, half, short, long 등의 이름을 기억해두어야 잘 활용할 수 있다.
2) Transformer의 decoder와 SASRec
여기서 자세히 정리하지는 않겠지만, Self-Attention mechanism은 주변 정보와의 attention을 학습하여 sequential한 예측을 하기 때문에, 예측에 관여하는 decoder의 경우 미래 정보를 사용하지 않도록 masking을 해주는 과정이 필요하다. 의미 없는 숫자 혹은 mask 토큰 등으로 미래 정보를 가려놓는다고 생각하면 된다.
여기서 정리해 볼 내용은 Transformer의 decoder를 활용한 추천 모델인 SASRec(Self-Attentive Sequential Recommendation)의 구현 중 일부로, Self-Attention block에 활용되는 mask 생성 과정이다.
[1, 2, 3, 4, ?] # ? = 10
## Train ##
# 1)
[1, ?, ?, ?, ?] # next_target = 2
# 2)
[1, 2, ?, ?, ?] # next_target = 3
# 3)
[1, 2, 3, ?, ?] # next_target = 4
# 4)
[1, 2, 3, 4, ?] # next_target = 10위의 예시처럼 [1,2,3,4]의 sequence를 SASRec으로 학습시킨다면, 모델은 차례로 1) ~ 4)의 input을 활용해 target을 예측하도록 학습하게 된다. 이 과정에서 바로 다음 item이 무엇인지 예측할 때는 (이미 알고 있는) 뒷단의 정보를 활용하면 안되기 때문에, ?와 같이 masking 해 줄 필요가 있다. 즉, 하나의 input seqeunce [1,2,3,4]를 활용하기 위해 4개의 masked seqeunce가 필요한 상황이다.
def make_attention_mask(input_ids):
# 다음 데이터를 예측에 활용하지 못하도록 look-ahead mask 생성(extended_attention_mask)
# 생성한 mask를 encoder의 input으로 활용 -> self-attention 과정에서 사용됨
attention_mask = (input_ids > 0).long()
print(attention_mask) # 1
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2) # torch.int64
print(extended_attention_mask) # 2
max_len = attention_mask.size(-1)
attn_shape = (1, max_len, max_len)
subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1) # torch.uint8
print(subsequent_mask) # 3
subsequent_mask = (subsequent_mask == 0).unsqueeze(1)
subsequent_mask = subsequent_mask.long()
extended_attention_mask = extended_attention_mask * subsequent_mask
# fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
return extended_attention_mask이를 구현한 위의 코드를 이해하기 위해 torch의 기본 연산들을 살펴보자.
① tensor.long()
주어진 tensor를 Long type으로 변환한다. input_ids > 0 이 BoolTensor를 생성하므로, 이를 다시 LongTensor로 변환해주기 위해 사용됐다. input인 tensor([1,2,3,4])에 대해 # 1의 출력은 아래와 같다.
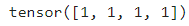
② squeeze와 unsqueeze
size가 1인 차원을 추가하거나 제거함으로써 tensor의 차원을 변경한다. unsqueeze(k)는 k번째 dimension 추가, squeeze(k)는 k번째 dimension을 제거한다. squeeze()에 따로 k를 인자로 주지 않으면, 존재하는 모든 size 1의 dimension을 제거할 수 있다. # 2의 출력은 아래와 같다.

저장할 정보는 2차원으로 충분하지만, self-attention 부분에서 다루는 input이 3차원 tensor이기 때문에 동일하게 3차원으로 만들어준다.
③ torch.triu()
input으로 주어진 2-D tensor의 upper triangular part를 반환한다. "diagnal = 0"이 default이며, 0번째 대각선을 기본으로 양수이면 위쪽, 음수이면 아래쪽 대각선을 기준으로 활용한다. 위 예시에서는 diagnal = 1이기 때문에 # 3에서 아래의 출력을 보여준다. (+1의 대각선과 그 위쪽의 원소들만을 출력, 나머지는 0)

이후 다시 반대로 0인 부분만을 1로 표현하고, # 2에 출력했던 것과 곱해 input에서 0이 아닌 부분에 대해서만 값을 남긴 뒤, 1인 부분들을 -10000이라는 값을 가지게 함으로써, 이후 attention block에서 이를 더해주어 아주 작은 값으로 만드는 과정을 통해 모델이 다음 것을 예측하는 데에 이후 정보를 활용하지 못하도록 하는 효과를 기대할 수 있다.
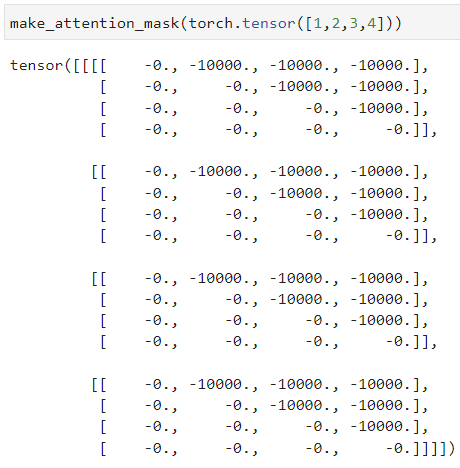
최종적인 출력은 아래와 같다. (unsqueeze(1)을 추가로 수행하여 4차원 tensor가 만들어진다.)