
기록하는삶
[파이썬/Python] 자연어처리 _ TfidfVectorizer 본문
CountVectorizer를 통해 자연어를 벡터화하는 경우 발생할 수 있는 문제점(의미 없이 자주 사용되는 단어의 가중치의 증가 등)을 해결하기 위한 방법 중 하나가 TfidfVectorizer다.
TfidfVectorizer
Tf, idf 두 가지를 먼저 이해해야 한다.
1) Tf(Term Frequency)
하나의 문서(문장)에서 특정 단어가 등장하는 횟수
2) Idf(Inverse Document Frequency)
Df(Document Frequency)는 문서 빈도. 특정 단어가 몇 개의 문서(문장)에서 등장하는지를 수치화 한 것. 그것의 역수가 idf다. 보통 그냥 역수를 취하기 보다는 아래처럼 수식화한다. 역수 개념을 사용하는 이유는, 적은 문서(문장)에 등장할수록 큰 숫자가 되게하고 반대로 많은 문서(문장)에 등장할수록 숫자를 작아지게 함으로써 여러 문서(문장)에 의미 없이 사용되는 단어의 가중치를 줄이기 위해서다.

Tf-idf 수치는 Tf 값과 Idf 값을 곱하여 구한다. 해당 연산을 거친 최종 Tf-idf 값은 0과 1사이로 만들어진다.
TfidfVectorizer 역시 sklearn에 내장되어 있다.
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [ 'you know I want your love', 'I like you', 'what should I do ' ]
tfidfv = TfidfVectorizer().fit(corpus)
print(tfidfv.vocabulary_)
print("="*100)
print(tfidfv.transform(corpus).toarray())
print("="*100)
print(tfidfv.fit_transform(corpus).toarray())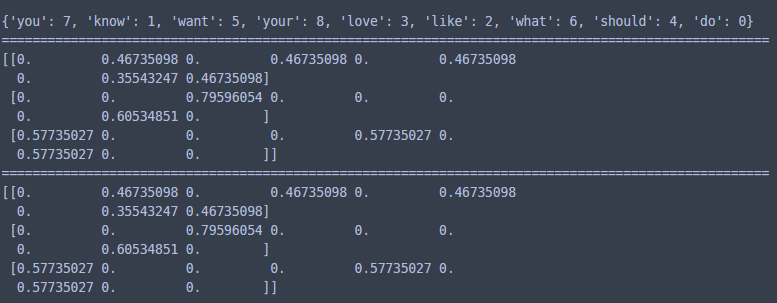
TfidfVectorizer.fit(text)를 통해 text가 가지고 있는 모든 단어를 BoW로 구성하고, 이 단어들에 대해 Tf-idf 값을 계산한 뒤 각 단어의 인덱스 위치에 Tf-idf 값이 들어간 벡터가 만들어진다. 이 과정에서 CountVectorizer와 마찬가지로 I, a 등 한 글자 단어는 사라진다. 특정 단어를 가지고 있지 않다면 Tf = 0 이므로 Tf-idf도 0으로 표현됨을 알 수 있다.
맨 아래 코드처럼 fit_transform을 이용 학습과 변환을 한 번에 진행할 수 있고, 그 결과를 print하기 위해서는 toarray를 이용해 바꾸어주어야 한다. 그냥 print하면 아래와 같은 결과가 보인다(상대적으로 보기 불편하다). (a,b)는 array로 만들었을 때 각 뒤에 나오는 tf-idf 값의 위치를 나타낸다. 표현되지 않은 값들은 모두 0이다.

이렇게 임베딩을 마치고 나면, 아래와 같이 문서(문장) 간 유사도도 수치화할 수 있다.
from sklearn.metrics.pairwise import linear_kernel
tfidf_matrix = tfidfv.fit_transform(corpus)
cosine_sim = linear_kernel(tfidf_matrix, tfidf_matrix)
cosine_sim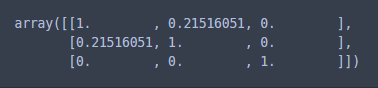
[Parameters]
① ngram_range, max_df, min_df, stop_words, analyzer, token_pattern, tokenizer : CountVectorizer와 동일 (이전 글 참고)
② max_features: 최대 feature(단어)의 수(int), default = None
모든 문서에 포함된 모든 단어를 이용해 BoW를 구성할 경우, 각 벡터들이 sparse해질 가능성이 존재한다. max_features = n 으로 설정할 경우 모든 문서를 기준으로 가장 많이 나온 상위 n개의 단어만을 사용해 임베딩을 진행한다. vocabulary = None 일 경우만 적용.
③ vacabulary: BoW, Mapping or iterable, default=None
어떤 BoW로 벡터화를 진행할 지 직접 지정할 수 있다. 예시는 아래와 같다.
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [ 'you know I want your love', 'I like you', 'what should I do ' ]
tfidfv = TfidfVectorizer(vocabulary = ["want", "love", "like"])
# print(tfidfv.vocabulary_) 사용 불가
print(tfidfv.fit_transform(corpus).toarray())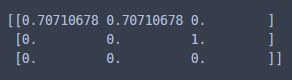
지정한 3개의 단어로만 벡터화한 것을 알 수 있다. 이 방식을 이용하면 TfidfVectorizer.vocabulary_는 작동하지 않는다.
④ binary: 이진화 여부(bool), default = False
binary = True로 설정할 경우 Tf-idf 계산 시 모든 tf 값을 0 or 1로 취급한다. 즉, tf를 특정 단어가 들어 있으면 1, 아니면 0으로 정한다. 이때 tf는 분자에만 해당하므로, 계산된 Tf-idf는 0 또는 1 이외의 숫자가 될 수 있다.
⑤ sublinear_tf: bool, default = False
sublinear_tf = True 로 설정하면 Tf 값을 'Tf -> 1 + ln(Tf)'로 변경하여 smoothing한다. 지나치게 큰 Tf 값을 갖는 이상치들이 존재할 때 효과적일 수 있다고 한다.
[Pros]
1. CountVectorizer가 갖는 단점 보완(자주 등장하는 단어의 가중치 축소)
2. 0과 1사이의 수치로 크면 자주, 작으면 덜 자주 등장한다는 것을 직관적으로 알 수 있음
[Cons]
1. 데이터 양이 크고 많은 경우, BoW의 length가 커 sparse한 벡터 표현이 만들어질 가능성이 큼
-> 전처리, stop_words, max_features 등을 이용해 잘 처리해야함
2. 차원이 너무 큰 벡터가 만들어질 가능성 존재
'AI > 파이썬(Python)' 카테고리의 다른 글
| [파이썬/python] EDA 기본(datetime type 변경, 중복값 제거, Null값 확인, unique 확인, 날짜정보 type변경, 히트맵) (0) | 2021.09.22 |
|---|---|
| [파이썬/python] 데이터 전처리(원핫인코딩_One-hot Encoding, 정규화, 표준화) (0) | 2021.09.22 |
| [파이썬/python] 정규표현식을 이용해 괄호와 괄호 안의 내용 삭제하기 (2) | 2021.09.13 |
| [파이썬/python] 클래스(Class), 클래스 상속 (0) | 2021.09.02 |
| [파이썬/Python] 자연어처리 _ Bow, CountVectorizer (0) | 2021.08.07 |



